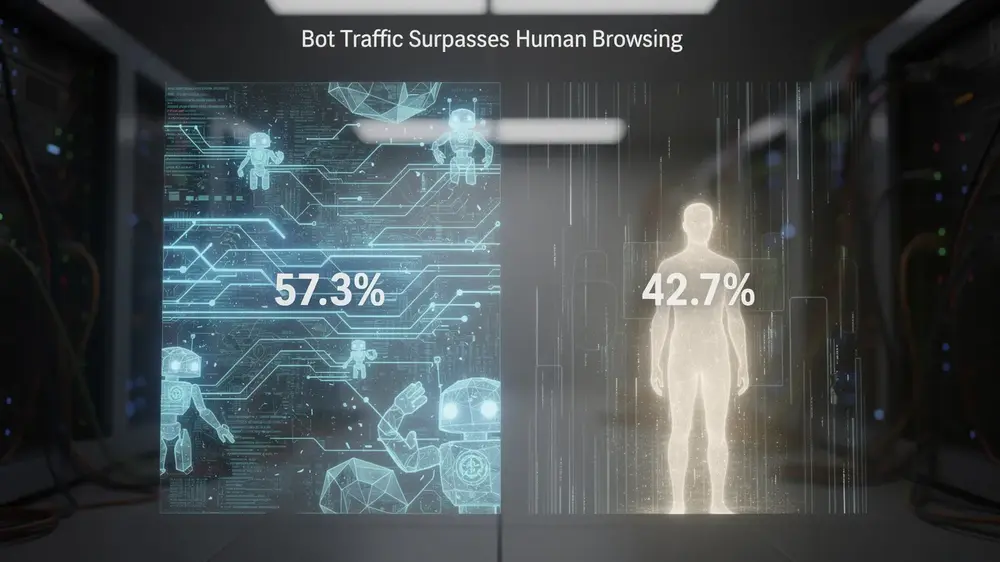
Cloudflare CEO Matthew Prince recently indicated that automated traffic has passed human browsing for HTML webpage requests, with bots accounting for about 57% of observed requests and humans accounting for about 43%. This is an important signal for publishers, ecommerce operators, and SEO teams, but it should not be read as a complete measurement of all internet activity. It is best understood as a strong directional indicator from one of the web’s largest infrastructure layers: machine-driven browsing is becoming too large to treat as background noise.
- Cloudflare’s observed data suggests bots now generate the majority of HTML webpage requests, with AI agents contributing to the acceleration beyond traditional crawlers.
- AI agents can request far more pages than a human user would during the same task, which makes pageviews, sessions, and engagement reports harder to interpret without filtering.
- Publishers and ecommerce teams should not judge performance from raw traffic alone, because automated requests do not necessarily produce ad clicks, purchases, leads, or loyal users.
- Structured data, clean site architecture, crawl control, and log analysis are becoming more important for both human usability and machine readability.
- The 57% figure is useful, but site owners should verify the same trend in their own analytics, CDN data, and server logs before making major strategic changes.
What Changed and Why It Matters
For years, most site owners treated bot traffic as something that happened around the edges of real user activity. Search engine crawlers, spam bots, monitoring tools, security scanners, and scrapers were already part of the web. What feels different now is the scale and purpose of automated browsing. AI agents are not only crawling pages for indexing or abuse. They are increasingly visiting pages to compare products, summarize information, extract facts, check prices, and complete multi-step tasks on behalf of users.
From an SEO and web operations perspective, this changes how we should read traffic data. A human researching a product, a service, or a travel option may visit a handful of websites before making a decision. An AI agent can request hundreds or thousands of pages during a similar task, often without clicking an ad, subscribing to a newsletter, submitting a lead form, or returning as a recognizable audience member. That creates a gap between measured traffic and business value.
I have seen this pattern in different forms across Korean ecommerce sites, Japanese service businesses, and European multilingual projects. The surface-level metric often looks positive at first: more requests, more sessions, more page activity. But when the same period shows no matching improvement in conversions, qualified inquiries, organic clicks, or repeat visits, the next step is not to celebrate traffic growth. The next step is to separate human demand from automated access.
This is why technical signals are becoming more important again. Understanding how schema markup communicates page meaning to crawlers and AI systems is no longer only a rich-result tactic. It is part of making content easier to interpret accurately when machines read pages at scale. The goal is not to write only for bots. The goal is to make useful content clear enough for both people and systems to understand without ambiguity.
The timing also matters. Prince had previously suggested that bot traffic could overtake human browsing in 2027, but the crossover appears to have arrived earlier than expected. That does not mean every website is already seeing the same ratio. News publishers, ecommerce sites, SaaS documentation, affiliate sites, and local business websites may experience very different patterns. Still, the direction is difficult to ignore: SEO teams need to evaluate traffic quality, not only traffic volume.
What We Know So Far About the Bot Majority Finding
The most useful way to read the Cloudflare figure is to separate confirmed observation from strategic interpretation. The reported number refers to HTTP requests for HTML webpage content observed through Cloudflare’s network. It does not automatically include every type of internet use, such as app activity, video streaming, API traffic, private platforms, or non-web environments. For site owners, that distinction is important because web analytics decisions should be based on the traffic layer that affects their own business model.
The core issue is not that bots exist. Bots have always existed. The issue is that a growing share of automated traffic now behaves more like browsing. AI agents may load full pages, read rendered content, follow links, compare information, and repeat the process across large numbers of sites. In practice, this can make automated activity look closer to human page consumption than older crawler behavior did.
For ecommerce operators, this matters because product pages may receive many requests without any buying intent. For publishers, it matters because pageviews may rise without a corresponding increase in ad yield, subscriptions, or loyal readership. For SEO teams, it matters because content performance reports may become noisy if bot traffic is mixed into the same dashboard as organic user behavior.
Cloudflare’s visibility is significant, but it is not the entire web. That is why I would avoid turning one headline number into an immediate universal rule. A more practical approach is to treat it as a warning signal and compare it with your own logs, analytics platform, CDN data, Search Console clicks, and revenue data. If those sources all point in the same direction, the business case for better bot segmentation becomes much stronger.
For teams that rely on GA4 or similar analytics tools, understanding how Google Analytics tracks SEO traffic is now a basic requirement. Analytics reports are useful, but they were not designed to explain every layer of automated traffic by default. When traffic patterns become unusual, server logs and CDN records often provide the missing context.
Who Is Affected and the Main Implications
The impact of AI-driven bot traffic is not evenly distributed. A small brand site, a large publisher, a programmatic SEO site, and a cross-border ecommerce store will not experience the same risks. The common problem is that raw traffic becomes less reliable as a business signal unless the team knows what kind of visitor, crawler, or agent created it.
Revenue and Measurement Pressure
Ad-supported publishers face one of the clearest risks. If bot activity increases pageviews but does not produce ad clicks, video views, subscriptions, or return visits, revenue per session can decline even while traffic looks healthy. This creates internal confusion because editorial, SEO, and advertising teams may be looking at different versions of performance.
The same issue appears in ecommerce and lead generation. A product category page may receive a sudden increase in visits, but if add-to-cart actions, checkout starts, inquiries, and assisted conversions do not move with it, the traffic may not represent real demand. In cross-border SEO projects, this can become even more complicated because bot traffic may appear from hosting regions, data centers, VPN-heavy locations, or countries that do not match the target market.
Infrastructure and Strategy Shifts
For smaller and mid-sized sites, the server load created by automated agents can become a practical cost issue. A large publisher may have the infrastructure to absorb heavy request volume. A smaller business running on modest hosting may feel the pressure quickly, especially when agents crawl many large pages, faceted URLs, search result pages, archives, or thin parameter pages.
This is where crawl control becomes part of business operations, not only technical SEO. Reviewing robots.txt configuration best practices is a sensible first step, but it should not be treated as a complete protection layer. Robots.txt is a directive for compliant crawlers. It does not stop every unwanted bot. Serious traffic management may also require CDN rules, rate limiting, bot management, authentication for sensitive areas, and better URL hygiene.
SEO and content teams also need to adjust how they think about optimization. Optimizing only for human engagement signals is no longer enough, but optimizing only for machines is also a mistake. The stronger approach is to build pages that clearly answer the user’s intent, use structured data where appropriate, keep the site architecture understandable, and make the business value of each page measurable.
- Publishers: inflated pageviews, weaker ad yield, unclear audience quality, and higher infrastructure costs
- Ecommerce operators: product and category page requests that do not translate into buying behavior
- SEO teams: more pressure to distinguish search demand from automated content access
- Small site owners: possible bandwidth strain and distorted reporting from high-frequency requests
- Analytics teams: weaker attribution if bot traffic is mixed with human sessions
How Site Owners Can Verify This in Their Own Data
Before changing SEO strategy, site owners should verify whether bot traffic is actually affecting their own site. I would not recommend blocking aggressively based only on industry headlines. The better approach is to compare multiple data sources and look for patterns that repeat across them.
Start with the difference between visibility and behavior. Google Search Console shows how often your pages appear and receive clicks from Google Search. GA4 or another analytics platform shows what happens after a visit is recorded. Server logs and CDN logs show requests that may never become meaningful analytics sessions. When those three layers disagree sharply, the reason is often worth investigating.
- Compare Search Console clicks with analytics sessions. If sessions rise sharply while organic clicks stay flat, automated or non-search traffic may be influencing the report.
- Check user agents and request frequency in server logs. Repeated requests across many URLs in a short period often reveal crawler or agent behavior.
- Review geography and hosting patterns. Traffic from data center-heavy regions may not match your real target market.
- Segment landing pages by business value. If traffic grows mainly on low-conversion archives, tags, internal search pages, or parameter URLs, the increase may not reflect useful demand.
- Compare traffic with revenue signals. Ad revenue, affiliate clicks, form submissions, purchases, and email signups should be reviewed alongside sessions.
This process is especially important for multilingual and international websites. Korean users, Japanese users, and European users often search differently, compare information differently, and respond to different page structures. If automated traffic is mixed into the same report, it becomes harder to understand those market-specific behaviors. Good localization work depends on clean data.
Practical Response and Next Steps
The most practical starting point is to create a clearer separation between human engagement and automated access. This does not always mean blocking every bot. Some crawlers and agents may support discovery, indexing, monitoring, or legitimate business use. The question is which automated requests help your site, which ones create cost without value, and which ones distort decision-making.
- Audit analytics and server logs to identify traffic spikes, unusual user agents, low-engagement sessions, and high-frequency requests across large URL groups.
- Create reporting views or segments that separate likely human traffic, known crawlers, AI agents, and suspicious unknown automation.
- Review advertising and conversion reports using filtered data so business decisions are not based on inflated pageviews.
- Strengthen structured data and content clarity so important information is easier to interpret without relying on decorative layouts or vague copy.
- Assess hosting and CDN settings to manage request spikes, rate limits, cache behavior, and access rules for sensitive or low-value URL areas.
Structured data improvements should be paired with broader site quality work. A clear internal link structure, consistent templates, well-written headings, and useful page summaries all help both users and systems understand what each page is for. This also connects with crawl budget management, especially on larger websites where low-value URLs can waste resources and make important pages harder to prioritize.
For teams working on AI search visibility, this issue also connects with the broader AI Search Optimization framework. Rankings still matter, but they are no longer the only visibility layer. Citations, brand mentions, content extractability, topical authority, and source trust are becoming part of the same operational conversation. The safest strategy is not to chase every AI trend, but to build a site that is useful, verifiable, and technically understandable.
Signals To Watch
The 57% bot traffic figure is striking, but its long-term meaning depends on additional evidence. The first thing to watch is whether Cloudflare publishes more detailed methodology explaining how it separates AI agents, traditional crawlers, malicious bots, monitoring systems, and human browsing. Without that breakdown, the number is useful as a signal but limited as a direct planning benchmark.
Corroboration from other CDN providers, analytics vendors, ad verification platforms, and large publishers will also matter. If similar patterns appear across different site types and regions, the case for operational change becomes stronger. If the numbers vary widely, that variation may teach us something important about industry, geography, content format, and bot classification.
Publishers should pay close attention to ad yield, engagement quality, referral patterns, and revenue attribution. As automated browsing grows, measurement models built around human sessions may produce misleading signals. Understanding agentic browsing environments is becoming a practical concern for sites that depend on organic discovery, citations, and machine-readable authority.
Search platforms and AI assistants are another area to monitor. If AI systems continue to answer more tasks without sending users to the original website, content owners will need clearer strategies for attribution, licensing, brand visibility, and source credibility. At the same time, SEO teams should avoid tactics designed to manipulate generative responses. Google’s recent AI spam policy update reinforces a familiar principle: sustainable visibility depends on trust, not shortcuts.
A headline number can be useful, but it should not replace diagnosis. In the websites I have worked on across Korea, Japan, and Europe, the strongest decisions usually come from comparing several layers of evidence: search data, analytics data, server logs, conversion data, and market context. Bot traffic is now large enough that site owners should measure it seriously, but the response should be proportionate. Filter first, verify the business impact, then decide what to allow, limit, or block. (Hyogi Park, MOCOBIN)