X-Robots-Tag is an HTTP response header directive that controls how search engine crawlers handle web resources, including file types such as PDFs, images, and videos that standard HTML meta tags cannot reach. Because it operates at the server level, it gives site owners a reliable mechanism for managing indexing behavior across an entire domain, not just individual HTML pages.
- X-Robots-Tag is delivered at the server level before any page content is processed, making it effective for non-HTML file types that cannot carry embedded meta tags.
- Misconfigured directives, including overly broad regex patterns or conflicting instructions across robots.txt and meta robots tags, can silently remove important pages from search results.
- Applying the header to low-value files such as PDFs and media assets helps preserve crawl budget for the HTML pages that drive organic traffic.
- Server-side rules allow a single configuration to apply directives across thousands of URLs at once, making the approach practical for large or fast-growing sites.
- Regular audits of HTTP response headers and configuration reviews when new content types are introduced are necessary to keep directives accurate over time.
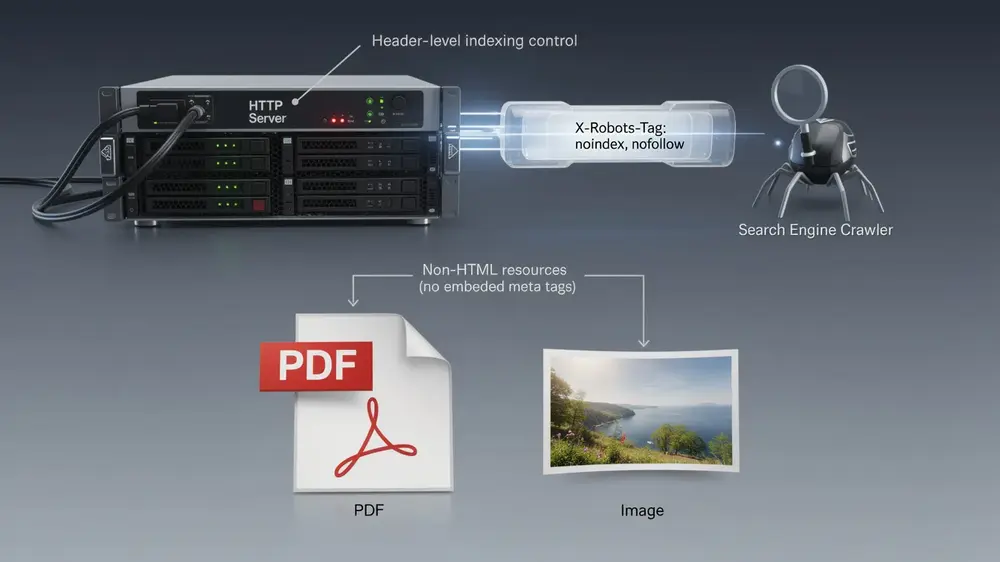
What is X-Robots-Tag and Why It Exists
X-Robots-Tag is an HTTP response header directive that instructs search engine crawlers on how to handle web resources during crawling, indexing, and serving. Unlike meta robots tags, which are embedded directly inside HTML documents, X-Robots-Tag operates at the server level, meaning it can be applied to any file type or URL pattern, including PDFs, images, videos, and JavaScript files.
The directive is delivered before the body content reaches the crawler. When a search engine bot requests a resource, the server sends the HTTP response headers first, so indexing rules take effect immediately, regardless of what the file contains. This makes it especially useful for non-HTML resources that have no capacity to carry embedded meta tags.
The basic syntax is straightforward. A typical header looks like this: X-Robots-Tag: noindex, nofollow. Multiple directives can be combined in a single header, and the header can also be scoped to specific crawlers by naming the bot before the directive.
X-Robots-Tag sits alongside robots.txt best practices and meta robots tags as part of a broader set of indexing controls. Where robots.txt manages crawler access at the URL level and meta robots tags handle HTML pages, X-Robots-Tag fills the gap for resources that cannot contain HTML. Together, these tools give webmasters layered, precise control over what search engines index and serve to users.
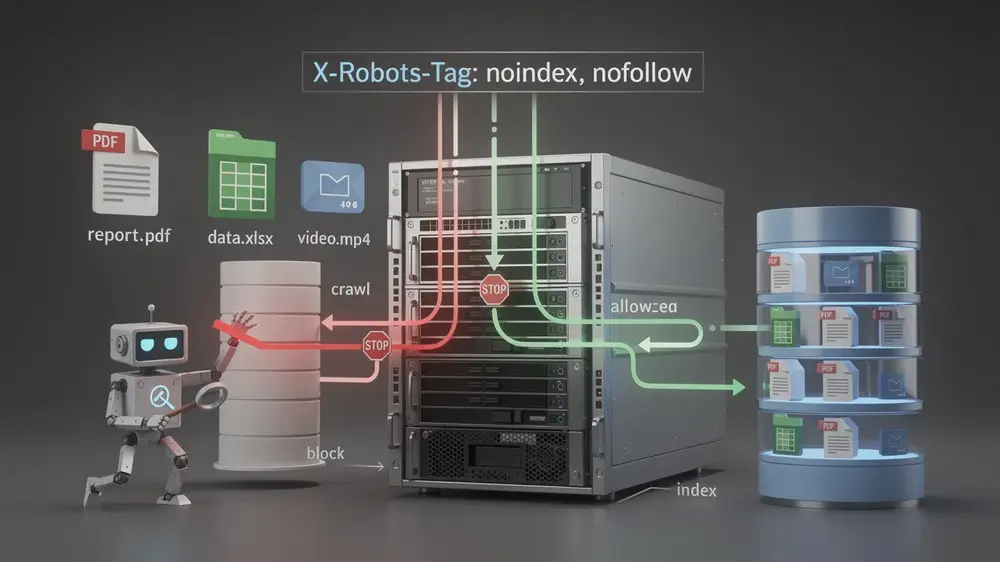
How X-Robots-Tag Impacts Crawling, Indexing, and SEO Performance
The X-Robots-Tag is a server-level HTTP header directive that gives site owners precise control over how search engines crawl and index content, particularly for file types that standard HTML meta tags cannot reach. PDFs, spreadsheets, media files, and dynamically generated resources all fall into this category. Without explicit instructions, search engines may index these files freely, consuming crawl budget and introducing content quality problems that are difficult to diagnose later.
One of its most practical functions is crawl budget optimization. When search engine bots spend time processing low-value supplementary files, they have fewer resources available for the HTML pages that actually drive organic traffic. Directing bots away from those files keeps crawl activity focused where it matters most.
Duplicate content is another area where this directive earns its place. If multiple formats of the same content exist, such as a web page and a downloadable PDF version, both can appear in search results and split ranking signals. The X-Robots-Tag lets you control which version is eligible for indexing, keeping signals consolidated. For a broader look at how page-level directives compare, the guide on meta robots tags and their SEO applications provides useful context.
Neglecting this header entirely carries real risk. Wasted crawl budget, unintended duplicate content exposure, and the indexing of low-quality resources can all quietly erode a site’s overall search performance over time.

How to Configure and Deploy X-Robots-Tag Directives
Adding X-Robots-Tag to your site requires working at the server level, not inside HTML files. For Apache servers, you edit the .htaccess file to inject the header into HTTP responses. For Nginx, the relevant changes go into nginx.conf. Both approaches tell the server to attach the directive automatically whenever a matching resource is requested, so crawlers receive the instruction before they process any page content.
One practical advantage of server-side configuration is the ability to use regular expressions for bulk control. Instead of setting rules resource by resource, you can write a single pattern that applies a directive across hundreds of URLs or file types at once. This is especially useful for non-HTML content. Targeting extensions such as .pdf, .jpg, or .mp4 lets you noindex entire categories of files without touching individual entries, which matters when managing duplicate content issues across large content libraries.
Before pushing any configuration to production, test it thoroughly in a staging environment. A misconfigured directive can accidentally block pages you want indexed, and that kind of error is easy to miss until rankings drop. Once deployed, use Google Search Console to verify that crawlers are reading the headers correctly. The URL Inspection tool can confirm whether a specific resource is being treated as noindex or nofollow based on the headers your server is returning.
Critical X-Robots-Tag Mistakes and How to Identify and Fix Them
Misconfiguring X-Robots-Tag is one of the more damaging technical SEO errors a site can carry silently. The consequences range from important pages disappearing from search results to crawlers behaving unpredictably across the entire site.
One of the most common problems is accidental broad blocking. When regex patterns or file path specifications are written too loosely, directives intended for a narrow set of URLs end up applying to pages that should remain fully indexed. A single misplaced wildcard can remove entire sections of a site from search visibility without triggering any obvious error.
Conflicting directives add another layer of risk. X-Robots-Tag, meta robots tags, and robots.txt can each carry different instructions for the same resource. Search engine crawlers generally follow the most restrictive directive they encounter, so a permissive X-Robots-Tag header means little if a conflicting meta tag or robots.txt rule is blocking the page anyway.
Incorrect server configuration can prevent headers from being transmitted at all. Syntax errors in server config files may cause the header to be silently dropped or, in worse cases, trigger server errors that block crawler access entirely. Non-HTML resources such as PDFs and images are also frequently overlooked during audits, which allows low-value content to consume crawl budget and dilute site authority signals over time.
Before pushing any changes to production, test configurations in a staging environment. Use header inspection tools to confirm that X-Robots-Tag directives are actually appearing in HTTP responses, not just assumed to be present.
From an editorial perspective, X-Robots-Tag errors are particularly difficult to catch because they produce no visible on-page symptoms. A site can lose significant search visibility before anyone connects the cause to a server configuration change made weeks earlier. Treating header audits as a routine checkpoint, not a reactive measure, is the more reliable approach.

Advanced X-Robots-Tag Strategies and Evergreen SEO Value
Unlike many tactics that lose relevance after algorithm updates, X-Robots-Tag addresses a fundamental need: controlling how search engines index content that exists outside standard HTML pages. That need does not disappear as search evolves. It grows more pressing as sites expand to include PDFs, videos, interactive JavaScript applications, and other rich media formats that cannot be managed through a simple meta robots tag.
Advanced practitioners take this further by combining X-Robots-Tag with conditional server logic. By serving different directives based on the requesting user agent, teams can give Googlebot one set of instructions while giving Bingbot or other crawlers a different configuration. This level of precision is part of what technical SEO as a discipline is built around, and it requires both server access and a clear content strategy to execute well.
Scalability is another reason this technique holds long-term value. A properly structured X-Robots-Tag system can be applied across thousands of URLs through server-side rules rather than page-by-page edits. As sites grow, that efficiency compounds.
Staying current still requires active maintenance. Recommended practices include:
- Running regular audits of HTTP response headers to confirm directives are being served correctly
- Monitoring for deprecated directive syntax as search engine documentation updates
- Reviewing configurations whenever new content types or site sections are introduced
The underlying principle remains stable. Precise, server-level indexing control gives SEO teams a reliable mechanism for managing crawl behavior regardless of what content formats or platform changes come next.