
Duplicate content in SEO describes a situation where identical or substantially similar content appears across multiple URLs, creating ranking uncertainty and splitting link equity in ways that reduce a site’s overall search visibility. Addressing this issue requires understanding both the technical sources of duplication and the specific signals, such as canonical tags, redirects, and URL management practices, that guide search engines toward a preferred version.
- Google does not formally penalize duplicate content but filters duplicate URLs from results, which produces the same practical outcome as reduced rankings.
- Most duplicate content originates from technical decisions such as URL parameter variations, mixed HTTP and HTTPS protocols, and session IDs rather than deliberate copying.
- Canonical tags signal a preferred URL to search engines but do not eliminate crawl budget waste, since search engines continue visiting duplicate pages to verify canonical consistency.
- Internal links pointing to non-canonical URLs send conflicting signals that can cause search engines to disregard canonical declarations entirely.
- Building canonical guidance into site architecture from the start is more efficient than resolving accumulated duplication issues after the fact.
Understanding Duplicate Content and Why It Exists in SEO
What Qualifies as Duplicate Content in Search Engine Evaluation
Duplicate content refers to identical or substantially similar content appearing across multiple URLs, either within a single website or across different domains entirely. Search engines encounter this situation and face a straightforward problem: they cannot easily determine which version deserves to rank, so they must make that judgment without clear guidance from the site owner.
A common misconception is that Google penalizes sites for duplicate content. That is not quite accurate. Google filters its results to avoid showing near-identical pages, which means affected pages receive lower visibility rather than a formal penalty. The practical outcome can feel similar, but the mechanism is different and worth understanding correctly.
When duplicate content exists without clear signals, three problems follow. Link equity fragments across multiple URLs instead of consolidating behind one strong page. Search engines face ranking uncertainty, so no single version achieves the visibility it could. And crawl resources get spent on redundant pages rather than unique content.
Why Duplicate Content Occurs Naturally in Website Architecture
Most duplicate content is not the result of deliberate copying. It emerges from ordinary technical decisions. Common sources include printer-friendly page versions, session IDs appended to URLs, HTTP and HTTPS versions of the same page running simultaneously, URL parameter variations used for tracking or filtering, and boilerplate text repeated across many pages.
The core issue is not the existence of these duplicates but the absence of clear signals telling search engines which version is preferred. That is precisely where canonical tags and URL canonicalization become essential tools for maintaining SEO authority.
How Duplicate Content Impacts Search Rankings and Crawl Efficiency
The Search Engine Clustering and Filtering Process Explained
When search engines encounter duplicate or near-duplicate pages, they group those pages into clusters and then algorithmically select one version to treat as canonical. The remaining versions are filtered out of search results to prevent repetitive listings. This filtering is not a formal penalty, but the practical outcome is identical: affected URLs effectively disappear from rankings.
The selection process is not always predictable. Without clear canonical signals, search engines may rotate between versions or choose a non-preferred URL, producing inconsistent rankings and unpredictable traffic patterns. That uncertainty alone is a strong reason to specify your preferred canonical version explicitly rather than leaving the decision to an algorithm.
Crawl Budget Waste and Link Equity Fragmentation Consequences
Duplicate pages also create a crawl budget problem. Search engines must visit multiple versions of the same content to verify canonical relationships, which reduces the frequency and depth of crawling for the unique, valuable pages on your site. For large websites, this can meaningfully slow down the indexing of new or updated content.
Link equity compounds the issue. When external sites link to different versions of the same page, the ranking signals are split unevenly across duplicates rather than concentrated on one URL. Consolidating those signals through a correctly specified canonical version strengthens ranking potential and stabilizes performance. Pairing this with a sound internal linking strategy reinforces which pages search engines should treat as authoritative, ensuring the preferred URL captures the full SEO value it deserves.
Diagnostic Process and Technical Solutions for Duplicate Content
Identifying Duplicate Content Using Search Console and Diagnostic Tools
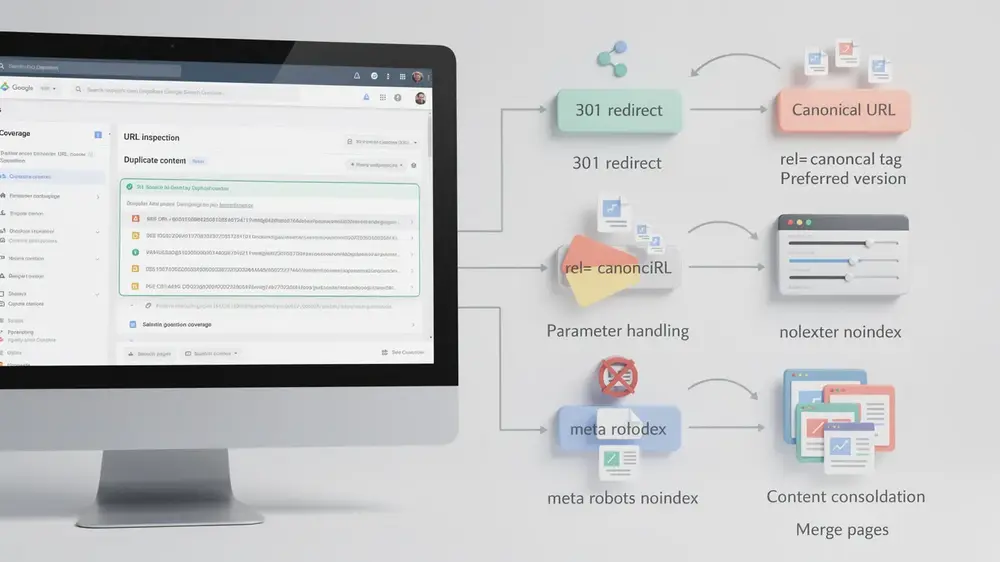
Start with Google Search Console. The Coverage report surfaces pages Google has identified as duplicates or has chosen not to index, while the URL Inspection tool lets you check how Google sees any individual URL. For content similarity across external sites, Copyscape remains a practical option. To find internal duplicates manually, run a site search using site:yourdomain.com followed by a specific phrase from the page in quotes. Any unexpected matches signal a duplication problem worth investigating.
Choosing the Right Technical Solution Based on Your Specific Scenario
The right fix depends on what you actually need the duplicate URL to do after the problem is resolved.
- 301 redirect: Use this when permanently consolidating URLs. It transfers link equity to the canonical version and physically moves users and search engines to the preferred page. It suits retired pages, URL restructures, and HTTP to HTTPS migrations.
- rel=canonical tag: Add this in the head section of duplicate pages pointing to the preferred version. It signals preference to search engines while keeping the page accessible to users. One limitation is that search engines still crawl these pages, so crawl budget waste is not eliminated.
- Parameter handling in Google Search Console: Configure this for URL variations created by tracking parameters, filters, or session IDs. You specify which parameters do not change page content so Google can ignore them during crawling.
- Meta robots noindex: Prevents indexing without redirecting users. Useful for faceted navigation, print versions, and internal search result pages. For directory-level control, robots.txt configuration lets you disallow crawling of specific duplicate content folders entirely.
- Content consolidation: Merge thin or overlapping pages into one comprehensive resource. Each remaining page should offer distinct information, perspective, or user benefit that justifies its existence.

Critical Mistakes in Duplicate Content Management and How to Avoid Them
Most duplicate content problems persist not because site owners ignore them, but because they rely on incomplete fixes or hold misconceptions about how search engines actually process duplicate signals. Understanding where these gaps appear is the first step toward closing them.
Why Canonical Tags Alone Are Not a Complete Solution
A widespread misconception is that adding a canonical tag immediately resolves a duplicate content issue. In practice, canonical tags are a signal of preference, not a directive. Search engines still crawl the duplicate pages to verify whether the canonical relationship is consistent. This means crawl budget continues to be spent on pages you do not want indexed, and if other signals contradict your canonical tag, such as internal links pointing to the non-canonical version, search engines may simply ignore your preference altogether.
There is also a related risk worth flagging: some site owners assume that having multiple versions of a page increases their chances of ranking. The opposite is true. Duplicate versions fragment ranking signals, so no single version accumulates enough authority to perform well.
Inconsistent URL Management and Internal Linking Errors
Several technical inconsistencies compound duplicate content problems at the URL level. As part of sound technical SEO practice, these areas require consistent attention:
- HTTP and HTTPS mixing: Without proper redirects or canonical tags, both protocol versions can exist as separate, fully duplicate sites, splitting all ranking signals in two.
- URL capitalization: Search engines treat example.com/Page and example.com/page as different URLs. Consistent capitalization in internal links, combined with redirects for variations, prevents silent duplication.
- Internal linking to non-canonical URLs: Every internal link pointing to a non-canonical version sends a conflicting signal that can cause search engines to discount your canonical declarations entirely.
- Boilerplate repetition: Excessive repeated content in headers, footers, or sidebars across many pages can trigger duplicate content detection. Minimizing repetitive elements and maximizing unique content per page reduces this risk.
Canonical tags are a useful tool, but they work best when every other signal on the site points in the same direction. A tag that contradicts your internal linking or sitemap is a signal search engines are likely to question, not follow. Treating canonicalization as a system-wide discipline rather than a page-level fix is what makes the difference. (Martha Vicher, mocobin.com)
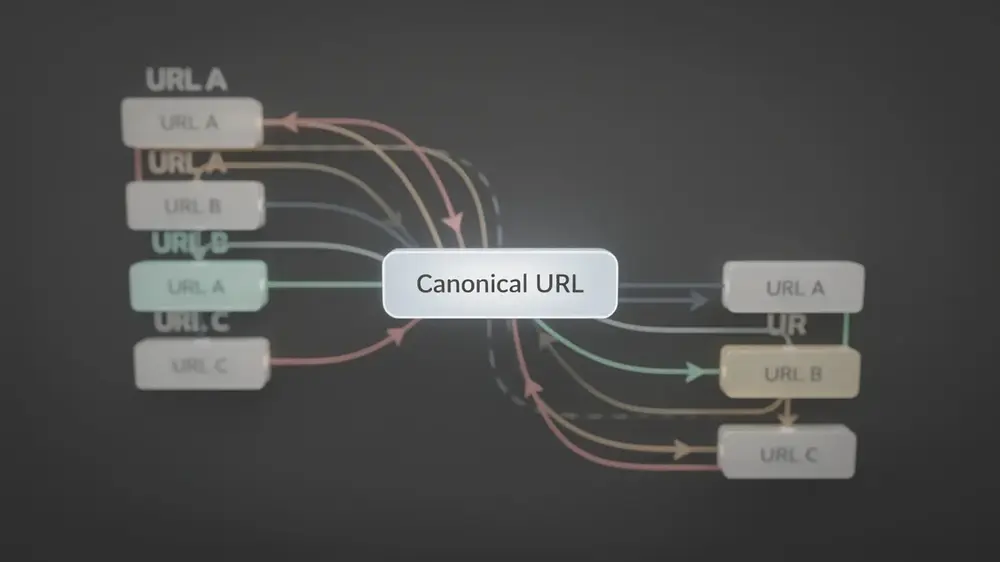
Advanced Duplicate Content Strategies and Evergreen Prevention Principles
Building Duplicate Content Prevention Into Site Architecture
Prevention is more efficient than remediation. Structuring your site correctly from the start reduces the volume of duplicate content issues that accumulate over time. Several architectural habits make a measurable difference:
- Point all internal links to canonical URLs consistently, never to redirect chains or parameter variants.
- Use HTTPS across every page without mixing protocols, since HTTP and HTTPS versions of the same URL can register as duplicates.
- Standardize URL capitalization through server-level conventions, as some servers treat uppercase and lowercase paths as separate resources.
- Organize tags and categories deliberately to avoid generating thin, near-identical archive pages that add little distinct value.
Faceted navigation and filtering systems deserve particular attention. Parameter combinations can silently generate hundreds of duplicate URLs. Careful use of canonical tags, parameter handling in Google Search Console, and selective indexing keeps user functionality intact without fragmenting your ranking signals. As part of broader on-page SEO fundamentals, these structural decisions shape how search engines interpret your entire site.
Ongoing monitoring matters equally. Regular reviews of Google Search Console’s Coverage report, automated crawls as content scales, and periodic content audits help catch new duplicates before they dilute authority.
The Evergreen Principle of Signal Consolidation and Clear Canonical Guidance
Algorithm updates change many things, but the core challenge of information retrieval does not change. Search engines need to identify the single best result for a query, and duplicate content complicates that process by splitting signals across multiple URLs. Consolidating those signals through canonical guidance addresses the problem at its root, which is why this principle holds regardless of what updates arrive.
Applying this thinking proactively means evaluating each new page before publication. If a proposed URL does not offer distinct information or a clear user benefit that justifies its existence separately, it belongs as an addition to an existing page rather than a standalone URL.
Authoritative Sources









