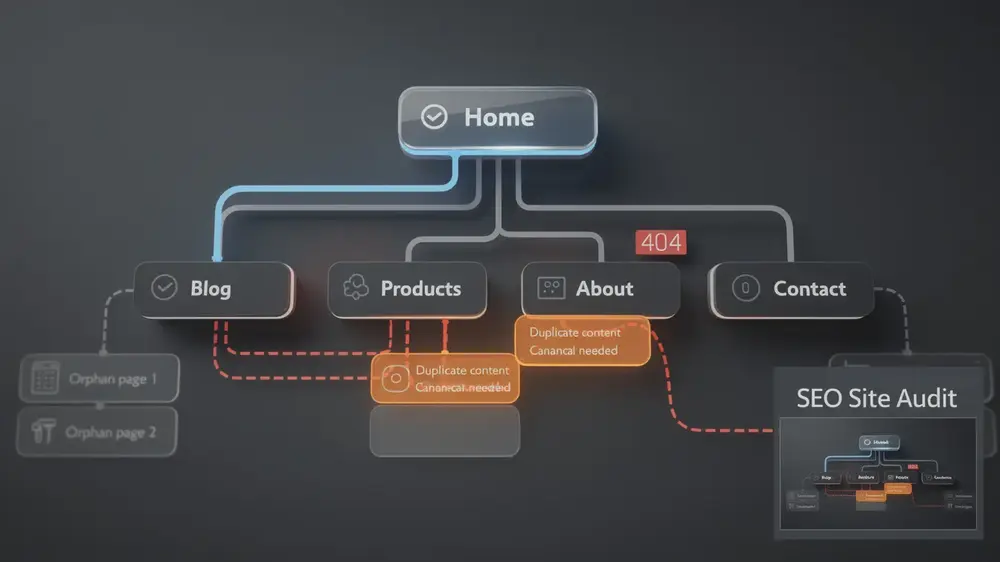
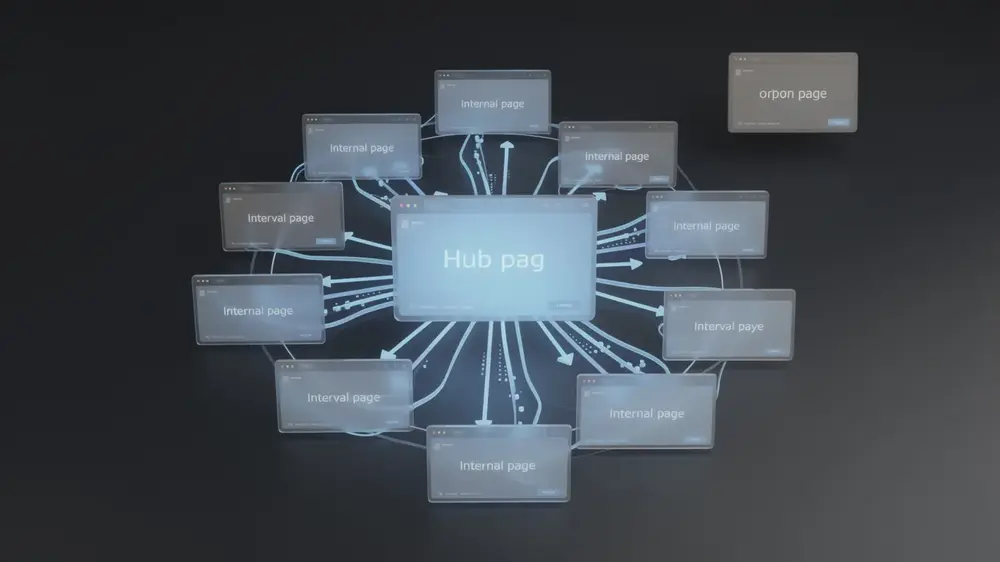
Orphan pages are published web pages with no inbound internal links, leaving them structurally disconnected from a site’s navigation and largely invisible to both users and search engine crawlers. Understanding how they form, how to detect them, and when to act on them is a practical requirement for any team managing site health and organic search performance.
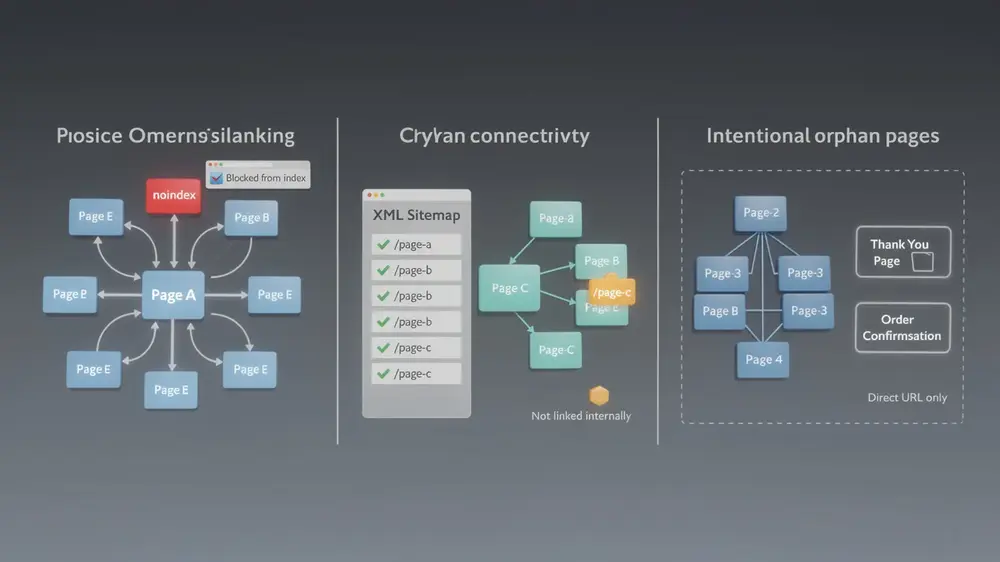
- An orphan page has zero inbound internal links, meaning crawlers following standard link pathways cannot reach it, regardless of whether it appears in an XML sitemap.
- Orphan pages reduce crawl priority, limit indexation chances, and sit outside the internal link equity flow that helps connected pages accumulate ranking strength.
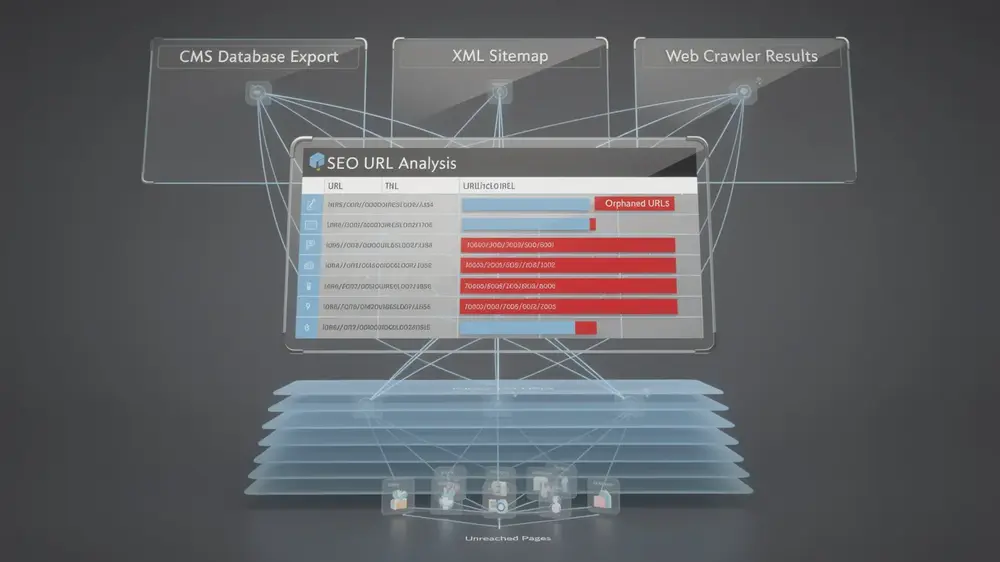
- Reliable detection requires combining a CMS export, XML sitemap data, and a full crawl tool, then cross-referencing all three sources to surface isolated URLs.
- Not every orphan page is a problem. Thank-you pages, checkout confirmations, and internal tool pages are often intentionally isolated and should not be linked into main site navigation.
- Orphan page management works best as a recurring discipline, with monthly or quarterly crawl schedules and automated alerts rather than a single one-time audit.
What Are Orphan Pages and Why Do They Exist?
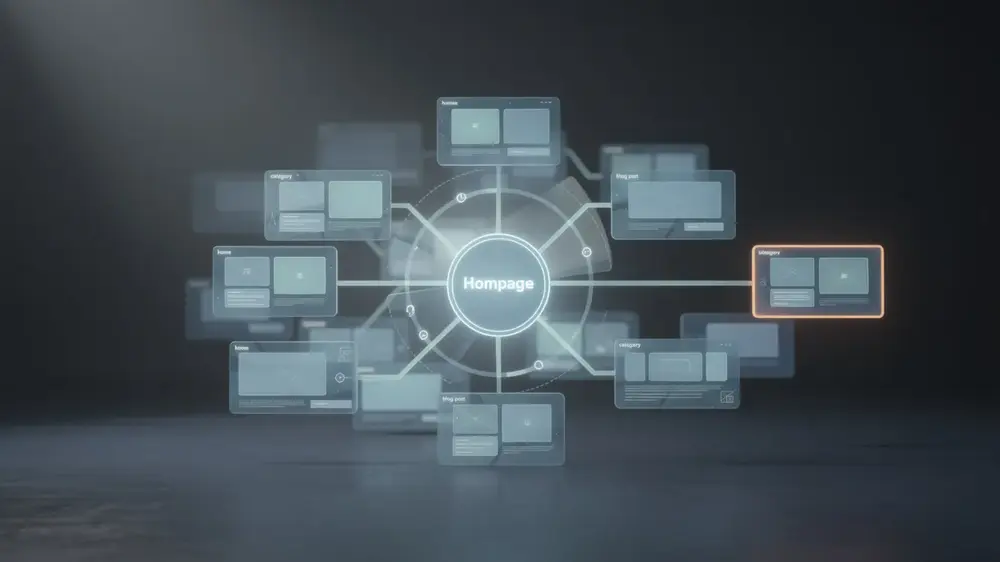
Orphan pages are published web pages that have zero inbound internal links, meaning no other page on the site points to them through clickable hyperlinks. Because of this, they sit completely outside the site’s navigation architecture. Users browsing normally cannot reach them, and search engine crawlers following internal linking pathways will not discover them through standard site traversal either. A page may still be accessible via a direct URL, an XML sitemap entry, or an external link, but that does not make it structurally connected to the rest of the site.
These pages are sometimes called “blind pages” or “isolated pages.” The key distinction is that they are technically published and live, yet completely disconnected from the site’s internal link structure.
Orphan pages tend to appear through three common mechanisms:
- Content management issues: Pages published in a CMS but never added to navigation, or archived pages left sitting in the database.
- Technical disconnects: Pages listed in an XML sitemap but not linked from any other page on the site.
- Site structure problems: Pages placed in subdirectories that have no parent-level navigation pointing to them.
In each case, the result is the same. The page exists in isolation, failing to integrate into the interconnected web of links that guides both users and search engines through a site’s content.
Why Orphan Pages Critically Impact SEO Performance and User Experience
Orphan pages create a compounding set of problems that stretch from technical SEO all the way through to business outcomes. Understanding each layer helps clarify why fixing them is worth the effort.
Crawlability takes the first hit. Search engines prioritize pages they can discover through internal links, and pages with no inbound links receive lower crawl priority as a result. A page that crawlers rarely visit has little chance of being evaluated for ranking, regardless of its content quality. This connects directly to how crawling and indexing work together to determine which pages actually appear in search results.
Indexation risk compounds the crawlability problem. Even pages listed in an XML sitemap face reduced indexation chances when they carry no internal link signals. Search engines use those signals to gauge page importance, and orphaned pages simply do not register as significant.
Link equity distribution is another casualty. Internal links pass authority and relevance throughout a site. Orphaned pages sit outside that flow entirely, missing the ranking power that connected pages accumulate over time.
From a user experience standpoint, visitors browsing a site normally cannot reach orphan pages through standard navigation. That isolation reduces engagement and conversions, making the content functionally invisible to most audiences.
The business consequence is straightforward: orphan pages represent content that generates minimal organic traffic and contributes nothing to site authority or business goals. They are, in practical terms, wasted resources and missed ranking opportunities sitting quietly on the server.
Complete Methodology for Finding and Identifying Orphan Pages
Detecting orphan pages reliably requires combining several methods rather than relying on a single tool or data source. The goal is to surface every URL that exists on your site but cannot be reached through internal link chains.
Building a Multi-Source Inventory
The foundational step is compiling a complete URL inventory from three sources: your CMS database export, your XML sitemap setup and structure, and a full site crawl using tools such as Screaming Frog, Semrush, or Botify. Comparing these lists against each other reveals URLs that appear in one source but not another, which is a strong signal of orphan status.
Crawl depth filtering adds a technical layer. When you run a full crawl starting from the homepage and following internal links, pages that return blank or null crawl depth values were never reached through link chains. Those are your orphan candidates.
Validation and Prioritization
Combining crawl data with Google Analytics, Google Search Console, and server logs strengthens accuracy considerably. Some orphaned pages are still indexed by Google or receive traffic through external links, making them higher priority than their internal link status suggests.
Once candidates are identified, confirm orphan status by verifying zero inbound internal links through link graph analysis. From there, prioritize remediation by ranking pages on traffic potential, keyword value, content quality, and current indexation status. Fixing every orphan simultaneously is rarely practical, so focusing on high-value pages first produces the most efficient results.
Critical Mistakes to Avoid When Detecting and Managing Orphan Pages
Orphan page management is more nuanced than it first appears, and three misconceptions in particular tend to undermine remediation efforts before they even begin.
Mixing Up Orphan Pages and Unindexed Pages
A page can be unindexed for reasons that have nothing to do with internal linking, including robots.txt blocking, noindex tags, or thin content issues. Adding internal links to a page blocked by a noindex directive will not restore its indexation. Before attempting any fix, verify the actual cause of the problem. This distinction sits at the foundation of sound technical SEO practice and prevents wasted effort on the wrong remediation path.
Overestimating What XML Sitemaps Can Tell You
XML sitemaps are hints to search engines, not proof of structural connectivity. A page can appear in a sitemap and still be completely orphaned within the site architecture. Crawl-based detection should always be the primary method for identifying orphan pages, with sitemap comparison used only as a secondary check.
Treating Every Orphan Page as a Problem
Some pages are intentionally isolated. Thank-you pages, checkout confirmation pages, and internal tool pages are designed to sit outside normal navigation. Attempting to link to them from the main site structure can actually create usability or tracking problems. The correction framework that works in practice involves auditing each orphan individually to separate accidental cases from intentional ones, then scheduling recurring crawls monthly or quarterly rather than relying on a single one-time audit. Site structures change, content is published, and links are removed over time, so orphan pages will accumulate without a consistent review cycle in place.
Rushing to fix every orphan page without first confirming the root cause is one of the most common ways remediation efforts backfire. A page isolated by design, such as a checkout confirmation or internal tool, should never be treated the same as one that ended up disconnected by accident. Diagnosis before action is what separates a productive audit from one that creates new problems.
Advanced Strategies and Long-Term Value of Orphan Page Management
Orphan page management is not a one-time audit task. It is an ongoing discipline that rewards teams who build structured, repeatable workflows around it. A practical action framework follows five sequential steps: audit by running a full site crawl with multi-source comparison, identify by filtering for pages with zero inbound internal links, prioritize by ranking pages according to traffic potential and keyword value and indexation status, remediate by adding internal links from relevant pages or removing pages that are intentionally orphaned, and monitor by establishing recurring crawls to catch new orphans as they appear.
Enterprise Implementation and Automation
At scale, manual periodic checks are not sufficient. Enterprise teams typically combine tools such as Screaming Frog, Semrush Site Audit, or Botify with API integrations that pull crawl data directly into analytics platforms. This enables automated detection workflows that flag newly orphaned pages as they occur. Configuring monthly or quarterly crawl schedules with alert systems represents current best practice, preventing gradual accumulation and keeping site structure consistently optimized.
Why This Practice Stays Relevant
The evergreen value of orphan page detection comes from a straightforward architectural reality. Regardless of how search engine algorithms evolve, pages without internal links will always face crawlability and discoverability challenges. That foundation does not shift. Advanced practitioners also recognize that orphan detection data feeds directly into broader decisions around core SEO principles and site structure, including content consolidation, information architecture improvements, and internal linking strategies that strengthen both site authority and user experience over time.

Advanced Strategies and Long-Term Value of Orphan Page Management
Orphan page management is not a one-time audit task. It is an ongoing discipline that rewards teams who build structured, repeatable workflows around it. A practical action framework follows five sequential steps: audit by running a full site crawl with multi-source comparison, identify by filtering for pages with zero inbound internal links, prioritize by ranking pages according to traffic potential and keyword value and indexation status, remediate by adding internal links from relevant pages or removing pages that are intentionally orphaned, and monitor by establishing recurring crawls to catch new orphans as they appear.
Enterprise Implementation and Automation
At scale, manual periodic checks are not sufficient. Enterprise teams typically combine tools such as Screaming Frog, Semrush Site Audit, or Botify with API integrations that pull crawl data directly into analytics platforms. This enables automated detection workflows that flag newly orphaned pages as they occur. Configuring monthly or quarterly crawl schedules with alert systems represents current best practice, preventing gradual accumulation and keeping site structure consistently optimized.
Why This Practice Stays Relevant
The evergreen value of orphan page detection comes from a straightforward architectural reality. Regardless of how search engine algorithms evolve, pages without internal links will always face crawlability and discoverability challenges. That foundation does not shift. Advanced practitioners also recognize that orphan detection data feeds directly into broader decisions around core SEO principles and site structure, including content consolidation, information architecture improvements, and internal linking strategies that strengthen both site authority and user experience over time.