Meta robots tags are HTML directives placed in a webpage’s head section that tell search engine crawlers whether to index a page, follow its links, cache it, or display it as a search snippet. For site owners managing large or complex websites, these tags provide page-level control that site-wide tools like robots.txt simply cannot replicate.
- Meta robots tags use the syntax <meta name=”robots” content=”…”> and must be placed inside the HTML head section to be read by crawlers.
- Common directives include noindex, nofollow, noarchive, and nosnippet, each controlling a distinct aspect of how a crawler handles the page.
- Blocking a page in robots.txt while relying on meta robots tags makes those tags invisible to crawlers, rendering the directives ineffective.
- Pairing noindex with follow allows a page to pass link equity through its outbound links without competing for rankings in search results.
- Noindex tags left over from staging environments are a common cause of traffic loss after a site launch and should be verified before any production deployment.

What Are Meta Robots Tags and Why Do They Exist?
Meta robots tags are HTML elements placed inside a webpage’s <head> section that communicate directly with search engine crawlers. Using the syntax <meta name=”robots” content=”…”>, they tell bots how to handle a specific page, covering indexing, link following, caching, and how much of the page content can appear as a search snippet.
The HTML Structure: Where Meta Robots Tags Live in Your Code
These tags sit within the <head> block of an HTML document, making them visible to crawlers before the page body is processed. The most fundamental directives you will encounter are noindex, nofollow, noarchive, and nosnippet. Each one addresses a distinct aspect of how a crawler should treat the page, giving you precise, page-by-page control rather than a blanket rule across your entire site.
Meta Robots Tags vs Robots.txt: Understanding the Difference
This page-level precision is exactly what separates meta robots tags from a robots.txt file. A robots.txt file sets site-wide crawling rules at the server level, while meta robots tags apply only to the individual page where they appear. For a practical comparison of how these two tools work together, the guide on robots.txt best practices covers the broader crawl management picture.
One point worth keeping in mind: meta robots tags are cooperative instructions, not security barriers. A well-behaved crawler like Googlebot will respect them, but they do not prevent direct access to a page or protect sensitive content from being reached by other means.
How Meta Robots Tags Impact Search Visibility and SEO Performance
Preventing Content Dilution: Protecting Your Search Result Quality
Meta robots tags give site owners precise, page-level control over how search engines index and display content. By blocking low-value pages such as filtered product listings, internal search results, or duplicate content variants, these tags prevent search engines from spreading indexing resources across pages that add little value. The practical result is that high-quality pages receive stronger priority in both crawling and ranking.
This approach complements other technical SEO tools. While canonical tags signal a preferred version of duplicate content, meta robots tags can remove a page from search results entirely when that is the cleaner solution. Together, they form a layered strategy for managing how search engines interpret a site’s content.
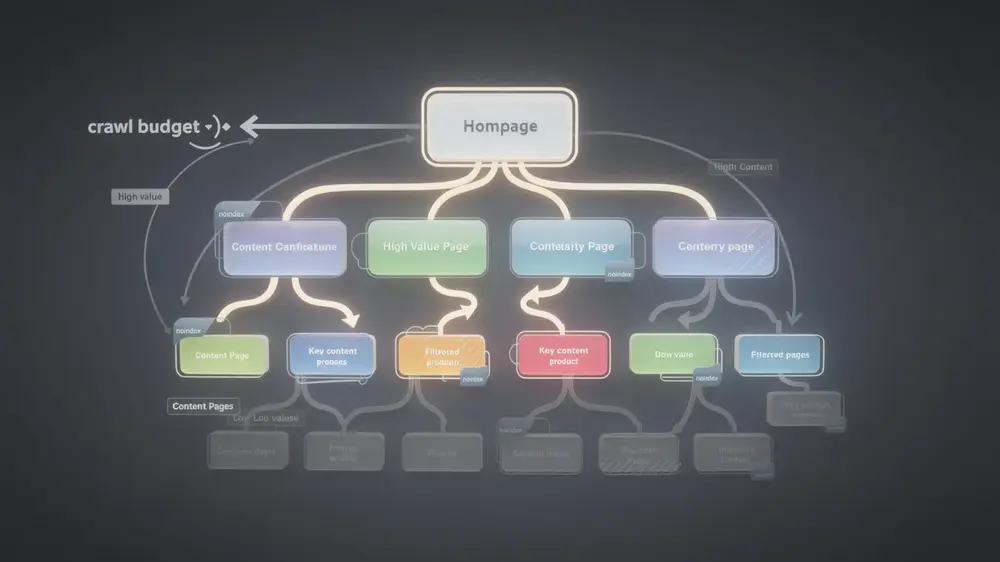
Strategic Crawl Budget Allocation Through Meta Directives
Search engines allocate a finite crawl budget to each website. When that budget is consumed by low-priority pages, important content may be crawled less frequently. Applying a noindex directive to utility pages frees up that budget for content that genuinely supports business goals.
Link equity management is another practical benefit. Using noindex combined with follow allows a page to pass authority through its outbound links while staying out of search results, which is useful for pages that serve internal navigation purposes but should not rank independently.
Unlike robots.txt, which restricts access at the directory level, meta robots tags apply restrictions one page at a time. This granularity ensures search engines interact with the site precisely as intended, keeping full control over what appears in search results.

Complete Guide to Implementing Meta Robots Tags Correctly
Meta robots tags give you direct control over how search engine crawlers handle individual pages. Placed inside the <head> section of an HTML document, the basic syntax follows this pattern: <meta name=”robots” content=”directive”>. Getting the placement and syntax right is the foundation before anything else.
Essential Meta Robots Directives: Syntax and Usage Examples
Each directive serves a distinct purpose. noindex tells crawlers not to include the page in search results. nofollow instructs them not to follow any links on the page. noarchive blocks cached versions from appearing in search results, while nosnippet prevents descriptive text from showing beneath a result. For finer control, max-snippet:X limits snippet length to a specific character count, for example max-snippet:150.
When you need to target a specific crawler rather than all bots, swap the name attribute accordingly. For instance, <meta name=”googlebot” content=”noindex”> applies only to Google, leaving other crawlers unaffected. This is useful when different engines require different handling for the same page.
Combining Multiple Directives: When and How to Use Comma Separation
Multiple directives belong in a single tag, separated by commas. A common combination is <meta name=”robots” content=”noindex, follow”>, which prevents a page from being indexed while still allowing link equity to pass through its outbound links. This approach is particularly relevant when managing duplicate content issues across your site, where you want crawlers to follow links but not index near-identical pages.
For non-HTML files such as PDFs or images, meta tags are not an option. Instead, use X-Robots-Tag HTTP headers to deliver the same directives at the server level. Finally, if you have noindexed a page, keep it in your XML sitemap temporarily. Search engines need to revisit the URL to confirm removal before dropping it from their index entirely.
Critical Meta Robots Tag Mistakes to Avoid and How to Fix Them
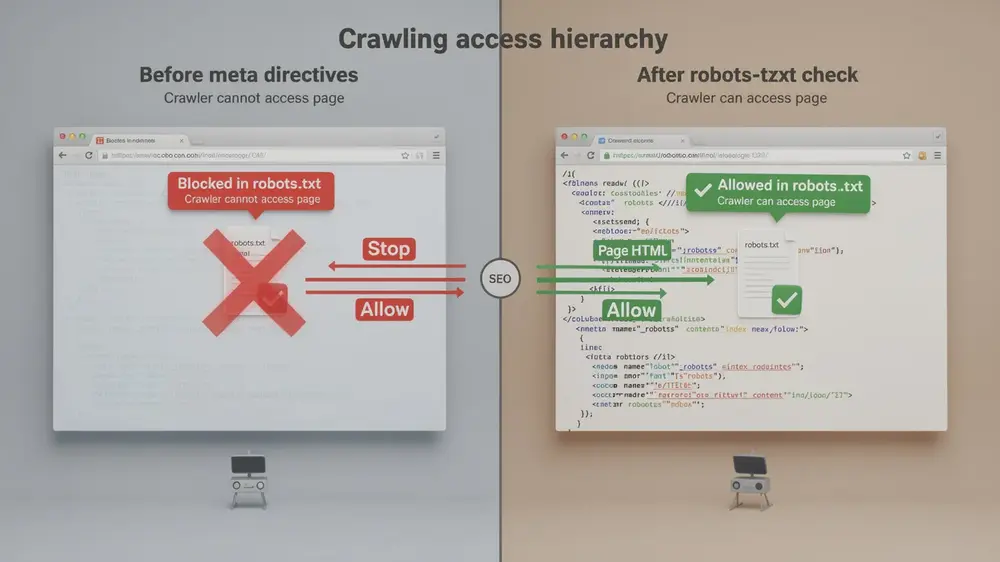
The Robots.txt Blocking Trap: Why Your Meta Tags Might Be Invisible
One of the most counterproductive errors in technical SEO is blocking a page in robots.txt while also relying on meta robots tags to control crawler behavior. If a crawler cannot access the page at all, it cannot read the HTML head section where the meta tag lives. The directives become completely ineffective. The fix is straightforward: adjust robots.txt to allow crawling first, then let the meta tag handle the specific instruction. Understanding how crawlers allocate access is closely tied to crawl budget management, which makes this interaction worth understanding carefully.
A separate but related error is placing meta robots directives inside robots.txt itself. Those directives belong exclusively in the HTML head section or as HTTP response headers. Robots.txt has its own syntax and does not process meta tag instructions.
Multiple conflicting meta robots tags on the same page create another problem. When a page carries contradictory instructions, crawler behavior becomes unpredictable. Each page should carry only one clear, consistent directive.
Staging to Production Checklist: Removing Development Noindex Tags
Forgotten noindex tags from staging environments are a frequent and painful cause of traffic loss after site launches. Before any production deployment, verify that all noindex directives added during development have been removed. Use view-source inspection to check the HTML head directly, and cross-reference with Search Console index coverage reports to confirm pages are being indexed as expected.
Finally, meta robots tags are not a security mechanism. A determined user can still access a page that carries a noindex or nofollow tag. Sensitive content requires proper authentication controls, not crawler directives.
From an editorial perspective, the staging-to-production oversight is worth treating as a formal checklist item rather than an afterthought. A single forgotten noindex directive can quietly suppress pages that took months to build authority, and Search Console coverage reports alone may not surface the problem immediately enough to prevent measurable ranking loss.
Advanced Meta Robots Strategies and Evergreen SEO Value
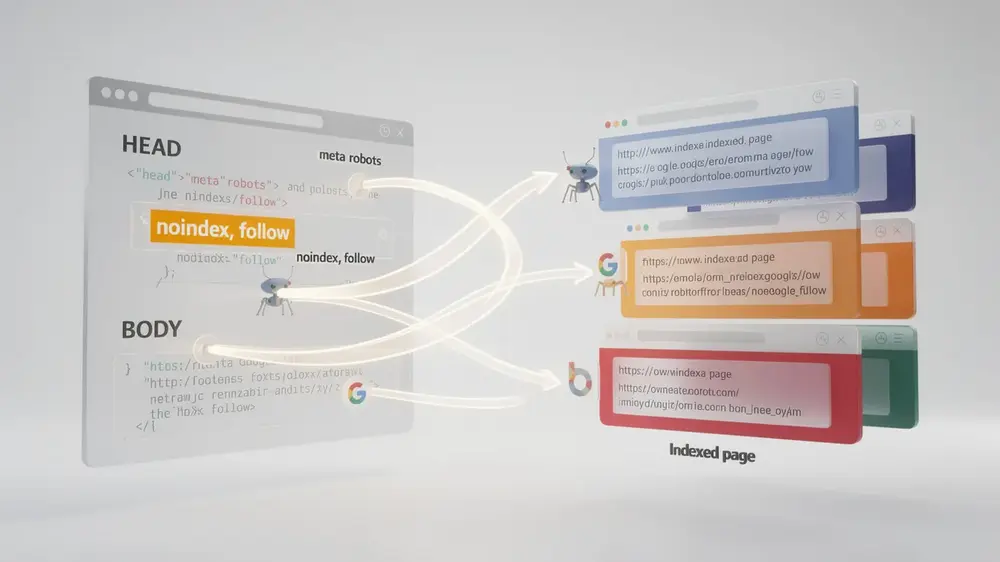
Strategic Link Equity Flow: The Noindex-Follow Combination Explained
One of the more sophisticated uses of meta robots tags involves pairing noindex with follow on the same page. This combination tells search engines not to include the page in their index while still allowing crawlers to follow its outbound links. The practical result is that the page passes link equity to other pages without competing for rankings itself. Pagination pages, internal filter pages, or certain category archives are common candidates for this treatment, since they hold little standalone search value but often link to content that does.
A related expert technique involves targeting specific crawlers with dedicated meta tags. When different bots require different handling, such as Googlebot versus Bingbot, you can write separate directives for each rather than applying a blanket rule. This level of precision reduces unintended consequences across search engines with distinct crawling behaviors.
Why Meta Robots Tags Remain Essential in Modern SEO
Meta robots tags stay relevant because page-level crawler control is a constant need regardless of algorithm updates or new search features. The underlying requirement, telling specific bots what to do with specific pages, does not disappear as search evolves. Understanding this tool also builds the foundational knowledge needed for more complex technical SEO implementations and crawler management strategies.
For large sites especially, regular audits of meta robots tag usage are worth scheduling. Tags set during a site migration or product launch can drift out of alignment with current business goals, quietly blocking valuable pages or leaving thin content indexed longer than intended.