The Google Search Console Page Indexing Report is often the first place to check when a page has been published but still does not appear in Google Search. It helps site owners, editors, and SEO teams separate normal URL exclusions from real indexing problems, such as accidental noindex tags, blocked crawl paths, broken URLs, duplicate canonical signals, or sitemap inconsistencies.
In practical SEO work, the value of this report is not simply knowing whether a URL is indexed. Its real value is helping you decide which URLs deserve action, which URLs can be ignored, and which technical signals need to be checked before requesting validation. That distinction matters because not every excluded URL is a problem, and not every indexed URL is necessarily performing well.
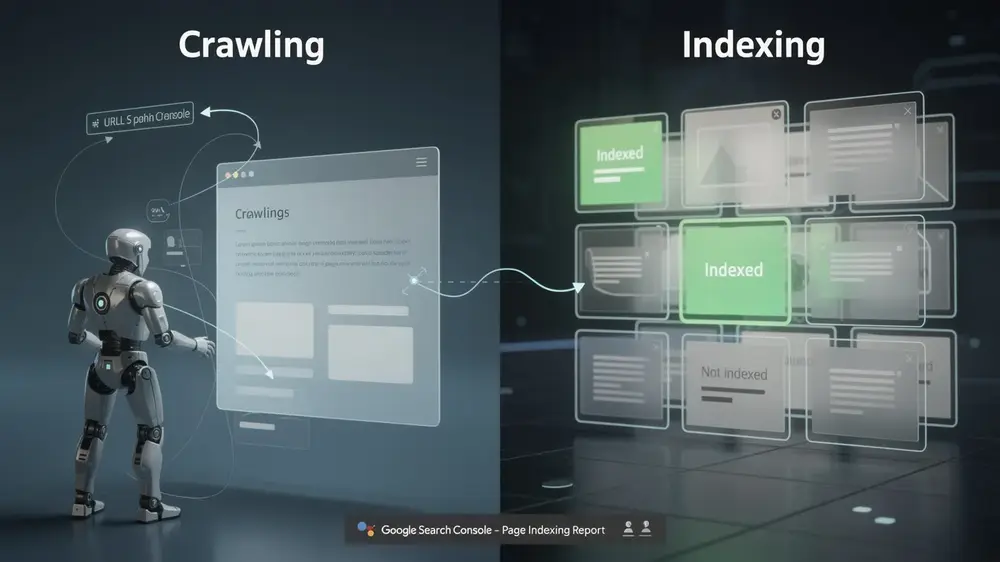
- Crawling and indexing are separate stages. A page that Google has crawled is not automatically added to the index, and only indexed pages can appear in search results.
- The Page Indexing Report identifies specific reasons for exclusion, such as robots.txt blocks, noindex directives, duplicate canonical signals, soft 404s, or 404 errors, each of which requires a different response.
- Not every non-indexed URL needs fixing. Pages like thank-you pages, internal search results, filtered URLs, or staging content are often intentionally excluded and should be reviewed in context.
- The aggregate report works best alongside the URL Inspection tool, which provides page-level detail on crawl status, canonical selection, indexing eligibility, and last crawl date.
- Indexing status can shift after site migrations, CMS updates, theme changes, template edits, or plugin changes, so routine monitoring is safer than treating indexing as a one-time audit task.
What Is the Google Search Console Page Indexing Report and Why It Matters
The Page Indexing Report is Google’s official reporting area in Search Console for understanding which URLs on your site are indexed, which are not indexed, and why Google has grouped them that way. For anyone managing organic search as a serious traffic channel, this report is not a decorative dashboard. It is one of the most practical ways to understand whether Google can actually store and serve your pages in search results.
To use the report properly, it helps to separate crawling from indexing. Crawling is when Googlebot discovers and fetches a page through links, sitemaps, or other signals. Indexing is the later stage where Google analyses the page and decides whether to store it in the Google index. A URL can be discovered, crawled, and still remain outside the index. That is why a published page, or even a crawled page, is not automatically eligible to rank.
If a page is not indexed, it cannot appear in Google Search in the normal way, regardless of how carefully the title, headings, or body copy have been written. The Page Indexing Report makes that gap visible by showing the indexing status of URLs Google knows about and, where available, the reason behind exclusion. For an SEO team, this turns indexing work from guesswork into a more structured diagnosis.
For anyone building their knowledge of Google Search Console fundamentals, the Page Indexing Report is one of the most useful places to start. It translates Google’s handling of your URLs into a format that can be reviewed, prioritised, and acted on. The important point is to read the report with judgement: a status label is a clue, not always a complete diagnosis.

Why the Page Indexing Report Is Essential for SEO Success
The Page Indexing Report functions as a core diagnostic tool within a modern SEO workflow. At its most basic level, it tells you whether Google can include your pages in search results. Without that confirmation, even strong content, clean metadata, and good internal links may not lead to organic visibility.
One of the report’s most useful roles is identifying technical blockers. When important pages fail to appear in search results, the report can surface reasons such as a robots.txt configuration preventing Googlebot access, an unintended noindex directive, a not found response, or a canonical signal pointing Google toward a different URL. These issues look similar from the outside because the page is absent from search, but they require different fixes.
Skipping regular checks can create a quiet loss of visibility. A product page, a service page, a landing page, or a newly published article that Google cannot index has limited search potential, no matter how useful it is to readers. This becomes more important after site changes, because indexing issues often appear before traffic reports clearly show the impact.
For broader context, the report should be treated as part of your technical SEO foundations, alongside crawlability, redirects, structured data, HTTPS, internal linking, and page experience. It is not a replacement for a full technical review, but it gives a focused view of whether Google’s index can include the URLs that matter to your site.
From a brand and content operations perspective, this is also a communication issue. If a business invests in content but does not check whether key pages are indexable, the gap is not only technical. It affects campaign planning, reporting, editorial confidence, and stakeholder expectations. A calm indexing review helps teams avoid overreacting to harmless exclusions while still addressing genuine barriers quickly.

How to Read and Interpret Page Indexing Report Status Values
The Page Indexing Report groups URLs into status categories that show whether each page is indexed or not indexed, with reason labels for excluded URLs. Reading these labels correctly is the starting point for useful SEO diagnosis. A sensible workflow is to check the overall pattern first, identify whether affected URLs are important, inspect representative examples, and then validate only after a real fix has been made.
Common Status Values and What They Signal
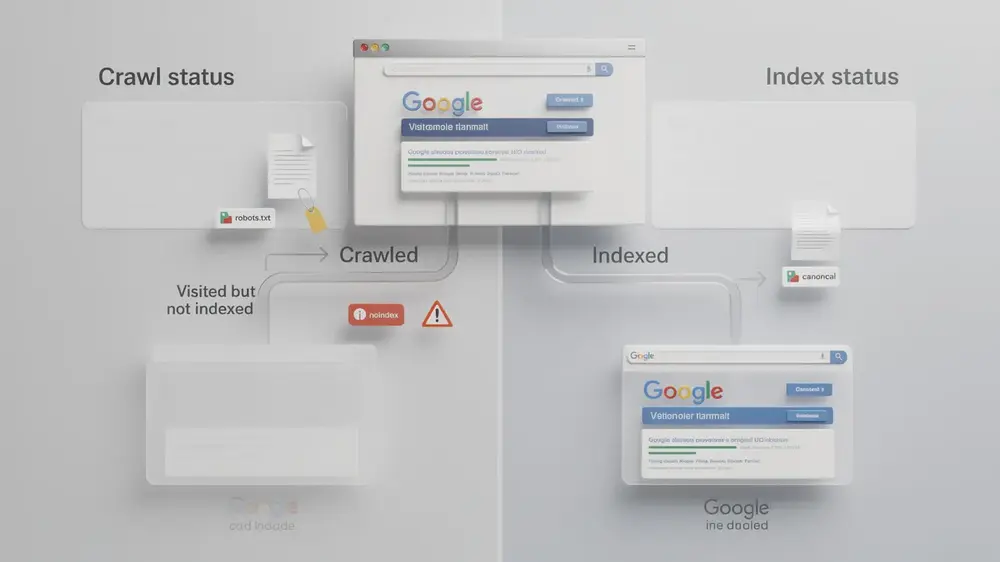
Status values fall broadly into indexed and not-indexed groups. Pages marked as indexed are eligible to appear in search results, although indexing alone does not guarantee rankings or traffic. Pages in the not-indexed group carry a reason label, and that label should guide your next check.
For example, Blocked by robots.txt usually means Googlebot is not allowed to crawl the URL. Excluded by noindex tag means the page itself, or its template, is telling Google not to index it. 404 (Not found) means the URL returned no usable page. Duplicate without user-selected canonical can suggest that Google found similar pages but did not receive a clear preferred version from the site. Each case needs a different response, so it is risky to treat every exclusion as the same type of problem.
Page Indexing Status: What to Check First
| Status | What It Usually Means | Recommended First Check |
|---|---|---|
| Blocked by robots.txt | Googlebot is not allowed to crawl the URL. | Check robots.txt rules and confirm whether the block is intentional. |
| Excluded by noindex tag | The page tells Google not to include it in the index. | Review the page source, SEO plugin settings, and template-level meta robots rules. |
| Duplicate without user-selected canonical | Google found similar URLs but no clear preferred version was selected by the site. | Check canonical tags, internal links, and sitemap URL consistency. |
| Discovered, currently not indexed | Google knows the URL exists but has not indexed it yet. | Review content quality, internal linking, crawl depth, sitemap inclusion, and duplication signals. |
| 404 Not found | The URL returns no usable page. | Restore the page, redirect it, or remove internal links if the URL is no longer needed. |
When duplicate or alternate URLs appear in the report, reviewing canonical tag signals is often safer than blocking URLs too early. Canonicalisation helps Google understand the preferred version of similar pages, while a poorly judged block can make it harder for Google to read the relationship between those URLs.
Supplementing the Report with the URL Inspection Tool
The aggregate report shows patterns across your site, but it does not always explain the full story for an individual URL. Using the URL Inspection tool for key pages gives you a more granular view of crawl status, canonical selection, indexing eligibility, and last crawl date. This is especially useful when one page matters commercially or editorially, such as a service page, a comparison article, a campaign landing page, or a recently updated guide.
To support accurate indexing over time, combine the report with a clear understanding of how crawling and indexing work, clean sitemaps that list only canonical URLs, consistent internal linking, and regular reviews of robots.txt and page-level directives. For publishers, a clean sitemap is particularly important because sitemap errors can slow discovery and make diagnosis harder. A separate sitemap auditing process can help confirm that important URLs are being submitted in a clean and indexable format.
Critical Mistakes to Avoid When Using the Page Indexing Report
One of the most common mistakes is treating “crawled” as the same as “indexed.” These are separate states. A URL that has been crawled has been visited by Googlebot, but it has not necessarily been stored in the search index. Confusing the two can lead to unnecessary fixes or misleading internal reports.
Another mistake is assuming that every non-indexed URL is a failure. Some pages are legitimately excluded by design, such as thank-you pages, internal search results, filtered archive pages, low-value parameter URLs, or staging content. If these are intentionally blocked or marked noindex, the report may simply be confirming that your technical setup is working as planned.
Context matters when reading status values. A label like “Duplicate without user-selected canonical” may look concerning, but the right response depends on the URL’s purpose. A duplicate printer-friendly page, a tracking-parameter URL, and a near-identical service page do not carry the same SEO risk. Before changing directives, check whether the URL should exist, whether users need it, whether it receives internal links, and whether it belongs in the sitemap.
The Page Indexing Report is a starting point, not a complete diagnostic tool. For a specific URL, the URL Inspection tool in Google Search Console provides more precise information. Relying only on aggregate report data can hide the actual cause of an indexing problem, especially when a template, plugin, or CMS setting affects multiple pages at once.
Skipping validation after a fix is another common weakness in the workflow. If you remove an accidental noindex tag, repair a broken page, or update a canonical tag, you still need to inspect the URL and monitor the report afterwards. Indexing changes can take time, and validation should be used to confirm that Google can process the corrected signal.
Finally, neglecting to review robots.txt and canonical signals alongside the report can leave persistent issues unresolved. Understanding the difference between noindex directives and disallow rules is essential because both can keep pages out of search, but they work differently and require different remediation steps.
The Page Indexing Report rewards careful reading rather than reactive fixes. A status label is a prompt to investigate, not a guaranteed diagnosis. The difference between a deliberate exclusion and an accidental one can only be confirmed by understanding the role of each URL, the surrounding technical signals, and the search value of the page itself.

Advanced Strategies and the Evergreen Value of Indexing Monitoring
Indexing health is not something a site solves once and then forgets. Site updates, search system changes, editorial restructuring, and technical errors can all shift the status of pages that were previously indexed. Regular monitoring of the Page Indexing Report helps teams catch these shifts before they become larger visibility problems.
A practical starting point is prioritising pages by business and editorial value. If a core product page, service page, lead generation page, or high-value guide appears as not indexed, it deserves prompt investigation. If an internal search URL or duplicate parameter URL is excluded, it may not need action at all. The report becomes more useful when you review it through a priority lens instead of treating all URLs equally.
Some statuses require more judgement than others. A page marked as discovered but not indexed may indicate that Google knows the URL exists but has not chosen to index it yet. The reason could relate to content quality, duplication, weak internal linking, crawl depth, or the overall importance of the URL within the site. In this situation, requesting indexing is rarely a complete strategy on its own. It is usually better to improve the page’s usefulness, strengthen internal links, and confirm that the sitemap and canonical signals are clean.
Combining aggregate report data with individual URL inspection gives a fuller picture. The report shows patterns at scale, while the URL Inspection tool explains what is happening to a specific page. Both perspectives are useful after a migration, a redesign, a CMS update, or a large content refresh.
If indexing issues appear across multiple templates or page types, move beyond single-URL checks and follow a structured technical SEO audit workflow to review crawlability, sitemap signals, internal links, redirects, canonical tags, and page-level directives together. This reduces the risk of fixing one symptom while leaving the wider system unchanged.
Maintaining clean technical SEO foundations remains central to all of this. Proper use of robots.txt, noindex directives, and canonical tags prevents conflicting signals that confuse crawlers. Alongside those, resolving broken links and fixing 404 errors reduces crawl waste and supports a healthier site structure.
The Page Indexing Report also has value beyond Google-only reporting. It encourages a useful habit: checking whether important content can be discovered, crawled, interpreted, and served. That habit is relevant whether a team is managing an English-language B2B site, a Korean content project, a Japanese brand site, or a multilingual publication aimed at several markets. Search intent, content format, and user expectations may differ by market, but the need for clean indexable pages remains consistent.
Regardless of how search algorithms evolve, the Page Indexing Report stays relevant because it answers a fundamental question: can Google include this content in search at all? Rankings, click-through rates, and conversions come later. Indexing is the gateway, and the report gives SEO teams a practical way to keep that gateway visible.
In a practical SEO workflow, the Page Indexing Report is especially useful after CMS updates, theme changes, migration work, or plugin changes. These updates can silently affect robots.txt access, canonical tags, or meta robots settings before traffic changes become visible in performance reports.