Before a page can earn impressions, clicks, or rankings, search engines first need to find it, understand it, and decide whether it deserves a place in the index. That is why crawling and indexing should be checked before keyword targeting, content expansion, or link building. If either process is blocked, even a well-written page may remain invisible in organic search.
- Crawling means a search engine can discover and access a URL, while indexing means the page has been selected for storage and potential visibility in search results.
- Not every crawled page is indexed. Search engines filter pages based on accessibility, uniqueness, canonical signals, quality, and overall usefulness.
- Robots.txt, noindex directives, canonical tags, XML sitemaps, and internal links serve different purposes and should not be treated as interchangeable tools.
- Large websites should monitor crawl waste from filtered URLs, tracking parameters, duplicate pages, redirect chains, and low-value templates.
- Google Search Console shows indexing outcomes, while server logs reveal how search engine bots actually move through the site.
What Are Crawling and Indexing in SEO?
Crawling and indexing are two separate stages in the way search engines discover, evaluate, and organize web pages. Together, they help search engines turn the open web into a searchable database without requiring every URL to be submitted manually.
Crawling is the discovery stage. Search engine bots such as Googlebot start from known URLs, then follow links to find additional pages. These links may come from a website’s own internal structure, external websites, XML sitemaps, or previously discovered URLs. During this process, bots request page resources and gather signals that help search engines understand what the page contains.
An updated XML sitemap can support this discovery process by listing important URLs and signaling when content has changed. However, a sitemap does not replace strong internal linking. Pages that are included in a sitemap but isolated from the rest of the website may still look less important than pages that are clearly connected through navigation, category pages, and contextual links.
Indexing happens after discovery. At this stage, search engines analyze the crawled content, check whether the page is accessible, identify duplicate or near-duplicate versions, evaluate canonical signals, and decide whether the page should be stored in the index. A page can be crawled many times and still remain excluded if it is thin, duplicated, blocked by indexing directives, or not considered useful enough for search results.
The practical difference is simple: crawling means a search engine found the URL, while indexing means the page has been accepted into the searchable database. This distinction matters because many SEO problems are not ranking problems at first. They are discovery, accessibility, or index selection problems.

Why Crawling and Indexing Matter Before Rankings
Crawling and indexing sit before every other SEO outcome. A page cannot rank, attract impressions, or generate organic clicks if search engines cannot first discover and store it. For this reason, technical SEO audits often begin by checking whether important pages are crawlable, indexable, and properly linked within the site.
One concept that becomes important as a website grows is crawl budget. In practical terms, this refers to how much crawler attention a search engine gives to a site within a certain period. Small websites rarely need to worry about crawl budget in a complex way, but larger websites with thousands of URLs, faceted navigation, old redirects, or duplicate templates can waste crawler attention on pages that do not support organic growth.
For example, an ecommerce or directory-style website may create hundreds of URLs through filters, sorting options, tracking parameters, or session IDs. If those URLs contain mostly the same content, crawlers may spend time processing variations instead of reaching new product, category, service, or guide pages. This is one of the most common ways crawl efficiency weakens over time.
Indexing applies another layer of selection. Search engines tend to prioritize pages that are accessible, unique, useful, internally linked, and supported by clear canonical signals. Duplicate pages, thin content, and pages with unclear purpose may be crawled but excluded from the index, which means they consume technical resources without producing search visibility.
Site structure and internal linking play a direct role in this process. Search engines use links to discover pages and understand relative importance. Before blocking low-value paths, review robots.txt best practices so you do not accidentally prevent crawlers from accessing pages or resources needed for proper understanding.
For time-sensitive content, efficient crawling can also help important updates enter search systems faster. It does not guarantee immediate ranking, but it reduces the technical friction between publishing, discovery, and potential visibility.

How to Optimize a Site for Better Crawling and Indexing
Getting search engines to find and index the right pages is not accidental. It requires a coordinated approach across site architecture, internal links, indexation controls, technical performance, and ongoing monitoring.
Start with an accurate XML sitemap. A sitemap should include important canonical URLs that you want search engines to discover and revisit. It should not become a storage place for every outdated, redirected, blocked, or low-value URL on the site. When sitemap URLs return errors or point to pages that should not be indexed, the sitemap can send mixed signals.
Next, review internal linking. Important pages should be reachable within a reasonable number of clicks from the homepage or other high-value sections. Contextual links from relevant articles, category pages, and service pages help crawlers understand which URLs deserve attention. Strong internal links also help users move naturally through related topics.
Use each directive for the right purpose. Robots.txt helps manage crawler access to selected areas of a website. A noindex directive is better suited for pages that users and search engines may access, but that should not appear in search results. Canonical tags help consolidate duplicate or near-duplicate URLs toward a preferred version. For duplicate pages, understanding how canonical tags work is often safer than blocking access too early.
Avoid blocking a URL in robots.txt if search engines need to crawl it to see a noindex directive or canonical tag. This is a common technical mistake. If the crawler cannot access the page, it may not be able to read the instructions placed on that page.
Technical performance also matters. Slow responses, repeated 5xx errors, redirect loops, and broken internal links can reduce crawl efficiency. Fast, stable servers do not guarantee indexing, but they reduce technical friction during crawling and rendering. Search engines need to access the page, load key resources, and understand the main content without unnecessary obstacles.
Finally, monitor results in Google Search Console. The Indexing reports, URL Inspection tool, sitemap reports, and crawl-related data can show whether pages are indexed, excluded, redirected, duplicated, or discovered but not indexed. For larger sites, combine this with log file analysis to see how bots actually behave, not only how pages appear in reporting tools.

Critical Mistakes That Block Crawling and Indexing
A common misconception is that every crawled page will automatically appear in search results. In reality, crawling is only discovery. Indexing is a separate decision. A page may be excluded because of a noindex directive, duplicate content, weak quality signals, poor accessibility, or unclear canonicalization.
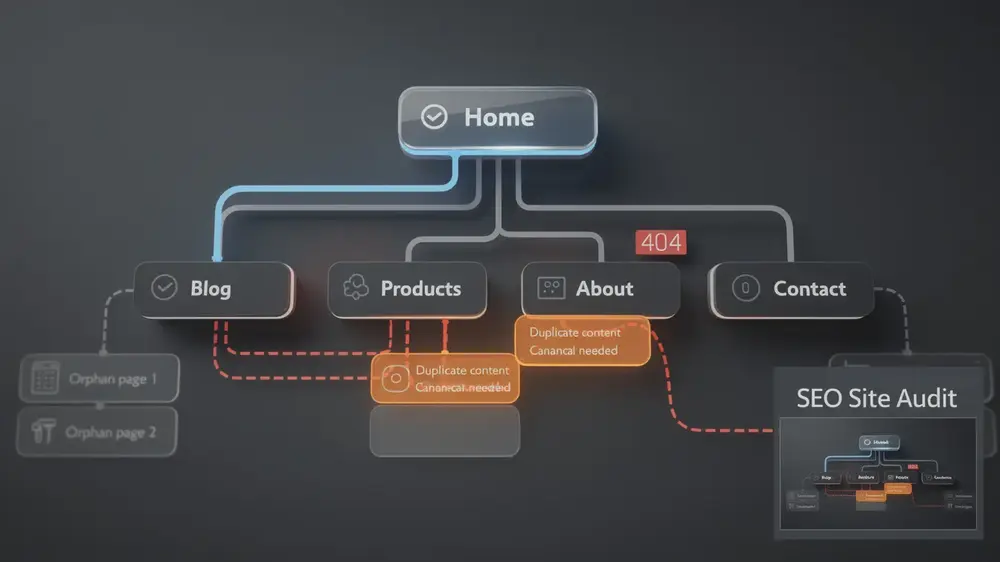
Another frequent issue is crawl budget waste. Faceted navigation, session IDs, UTM parameters, printer-friendly pages, and sorting options can generate large volumes of near-identical URLs. Search engines may spend crawler attention on these variations while more important pages remain under-discovered. A clear internal linking strategy helps guide crawlers toward pages that deserve indexing and search visibility.
In many technical audits, the issue is not that Google cannot crawl the entire site. The deeper problem is that crawler attention does not align with business-value pages. A website may show thousands of crawled parameter URLs while its main service pages, category pages, or long-form guides remain discovered but not indexed. Comparing Google Search Console data with server logs can reveal whether crawlers are spending time on the right URLs.
Technical blocks can make the situation worse. Misconfigured robots.txt files, accidental noindex tags, redirect loops, soft 404 pages, blocked resources, and slow server responses can prevent search engines from understanding content properly. These problems often appear after a redesign, CMS migration, plugin update, or template change.
Rendering should also be checked. Search engines need access to the resources required to understand the page, including important CSS, JavaScript, images, headings, titles, meta data, and visible main content. If JavaScript or CSS is blocked, or if critical content appears only after complex client-side rendering, the page may not be interpreted as intended.
Duplicate content creates another layer of risk. Search engines may crawl several versions of a similar page but index only one version. Without explicit canonical tags, clean internal links, and consistent sitemap signals, the selected version may not be the one you prefer.
Many crawling and indexing problems are caused by small configuration mistakes that stay hidden until organic visibility drops. Treating technical audits as a regular maintenance task, not a one-time cleanup, is what helps stable websites protect their search performance.

Advanced Crawling and Indexing Strategies for Larger Websites
For small websites, crawling and indexing management may be as simple as keeping pages accessible, avoiding accidental noindex tags, and maintaining a clean sitemap. For larger websites, the work becomes more strategic. The goal is not only to make pages crawlable, but to help search engines focus on the URLs that matter most.
Server log analysis is one of the most useful advanced methods. It shows which URLs bots request, how often they visit, what status codes they receive, and whether crawl activity is concentrated on valuable pages or wasted on low-value paths. Google Search Console provides a practical starting point, but log files give a more direct view of crawler behavior.
Advanced indexation work also requires stronger URL discipline. Parameter rules, canonical consistency, pagination handling, redirect cleanup, and sitemap hygiene all affect how search engines interpret a site. If the same content is available through several paths, the site should send consistent signals about which version deserves to be indexed.
Structured data, update frequency, and content freshness can support discovery and interpretation, but they do not replace basic accessibility. Search engines still need crawlable links, stable responses, and indexable content before enhanced signals can help. For news, data-driven resources, and regularly updated guides, this foundation becomes especially important.
JavaScript rendering has improved, but it does not remove the need for crawlable links, accessible main content, and unblocked resources. Critical content should be visible in the rendered HTML that search engines can process. When important content depends heavily on scripts, test representative URLs with the URL Inspection tool and confirm that the rendered version contains the content users and search engines need.
The long-term value of crawling and indexing work is stability. Algorithm updates may change how search engines evaluate relevance or quality, but discovery and index selection remain the entry point to organic visibility. A site with clean crawl paths, clear indexation rules, strong internal linking, and useful content is better prepared for both routine crawling and major search updates.