Noindex and disallow are two of the most consequential directives in technical SEO, yet they control entirely different stages of how search engines interact with a site. Using one when the other is needed, or combining both on the same page, can cause content to vanish from rankings or remain indexed when it should not be visible at all.
- Noindex controls visibility in search results by telling crawlers to access a page but exclude it from the index, while disallow blocks crawler access entirely at the robots.txt level.
- A page blocked by disallow cannot be deindexed through a noindex tag because the crawler never reads the instruction, meaning the page can still appear in search results.
- Google deprecated the noindex directive inside robots.txt in 2019, so page-level meta tags or X-Robots-Tag HTTP headers are the only supported methods for removing pages from the index.
- Blocking CSS, JavaScript, or image files in robots.txt prevents search engines from rendering pages correctly and can directly harm rankings.
- Regular audits in Google Search Console are necessary to confirm that noindex directives are honored and robots.txt rules are functioning as intended across the site.

Understanding Noindex and Disallow: Two Essential SEO Directives
These two directives sit at the core of how search engines interact with your site, yet they operate in fundamentally different ways. Confusing them is a common mistake that can lead to pages disappearing from search results entirely or crawl budget being wasted on content you never intended to hide.
What Each Directive Actually Does
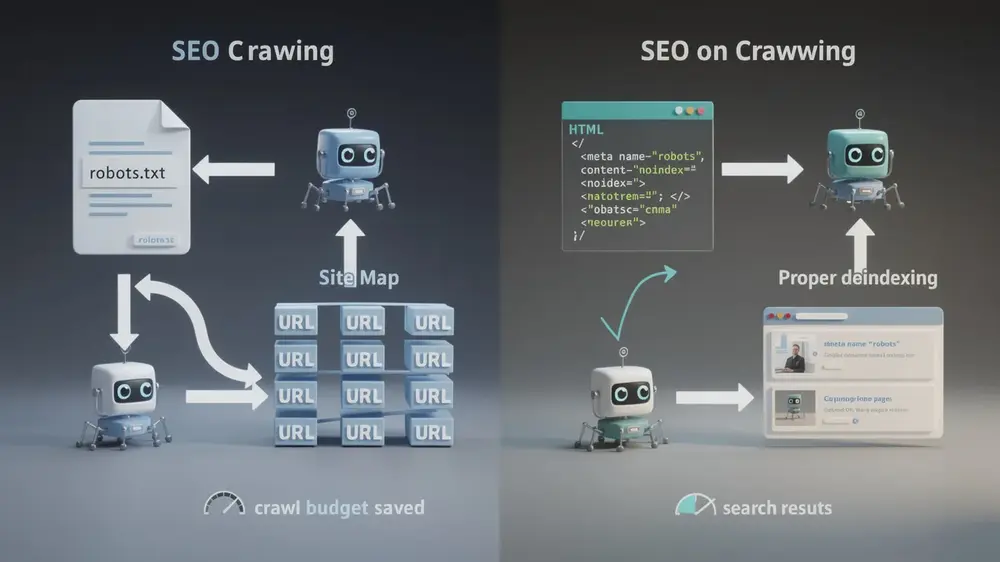
Noindex is a page-level instruction delivered through an HTML meta tag (meta name=”robots” content=”noindex”) or an X-Robots-Tag HTTP header. It tells search engines to access and read the page freely, but to exclude it from their index and search results. The crawler still visits the page. It simply does not list it.
Disallow works differently. Placed inside a site’s root robots.txt file for crawl control, it instructs compliant crawlers not to access specific URLs, directories, or URL patterns at all. The crawler is blocked before it can read any content on that path.
The Core Distinction: Access Versus Visibility
A useful way to frame this difference is through a library analogy. Noindex tells a librarian, “You can read this book, but do not add it to the catalog.” Disallow tells that same librarian, “Do not even enter this room.” One controls visibility in results. The other controls physical access to content.
Both directives serve complementary roles in managing crawl budget, protecting site resources, and shaping what appears in search results. They are not interchangeable, and using one when you need the other can produce outcomes you did not intend.
Why Noindex and Disallow Matter for Site Performance and Rankings
Two directives, noindex and disallow, form a foundational SEO pillar by controlling the functions that determine how search engines interact with your site. Crawling governs how search engines allocate resources to access your pages. Indexing determines which pages appear in search results and compete for rankings. Getting both right is not optional for sites that care about long-term search performance.
Noindex prevents low-value pages from appearing in SERPs. Thank-you pages, login areas, internal search result pages, and thin content all consume ranking authority without contributing meaningful value. When these pages enter the index, they dilute the authority that should be concentrated on your best, user-relevant content. Keeping them out of search results ensures ranking power stays focused where it matters.
Disallow works at the crawling stage. Admin panels, duplicate content paths, and certain JavaScript or CSS files consume crawl budget without any indexing benefit. Blocking them in robots.txt stops crawlers from wasting resources on areas that should never appear in search results.
Misuse of either directive creates real problems. Indexed private content becomes a security and reputational risk. Accidentally blocked pages can disappear from rankings entirely. Wasted crawl budget on irrelevant pages means priority content gets crawled less frequently.
Strategic implementation addresses these risks directly. It reduces index bloat, keeps search engine databases focused on high-quality content, and protects sensitive data while maintaining efficient crawl patterns across the site.
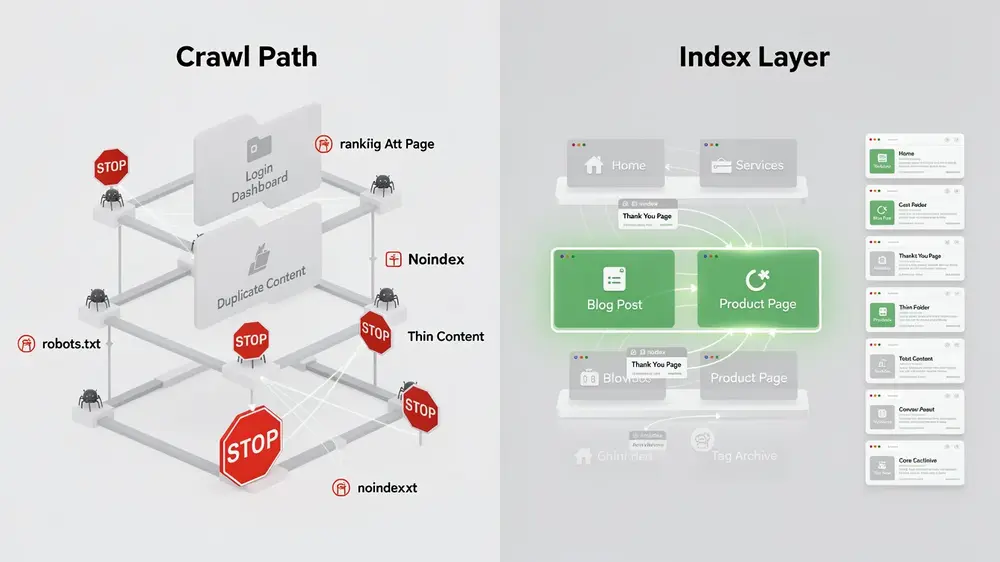
How to Correctly Implement Noindex and Disallow Directives
These two directives serve different purposes and follow separate technical workflows. Mixing them up, or combining them incorrectly, can leave pages indexed when you want them removed, or waste crawl budget on content that should never be fetched.
How Each Directive Works
With noindex, the crawler must first be able to access the page. It reads either the meta robots tag in the HTML head or the X-Robots-Tag HTTP header, then excludes the page from the index and search results. By default, links on that page are still followed unless you also add nofollow. This means the page must never be blocked by a disallow rule, otherwise the crawler cannot read the noindex instruction at all.
With disallow, the crawler checks the root robots.txt file before attempting any URL. If a path matches a disallow rule, the crawler skips it entirely without fetching the content. The page can still appear in search results if external links point to it, typically shown as a result with no description or “no information available.”
When to Use Each One
Use noindex alone (without disallow) for pages like internal search results, paginated content, or low-quality but linkable pages. These need to stay crawlable so search engines can process the directive. Use disallow for resource-heavy areas such as admin panels, duplicate content sections, or certain JavaScript and CSS files, purely to save crawl budget. Never use disallow on a page you want removed from search results.
For complete deindexing, first remove any disallow rules blocking the page, then add the noindex directive. Wait for search engines to crawl and process it. You can use the Google Search Console Removals tool as a temporary measure. Only after deindexing is confirmed should you consider re-adding a disallow rule. This workflow pairs well with understanding how canonical tags guide search engines to preferred page versions, since both tools shape how content is discovered and indexed.
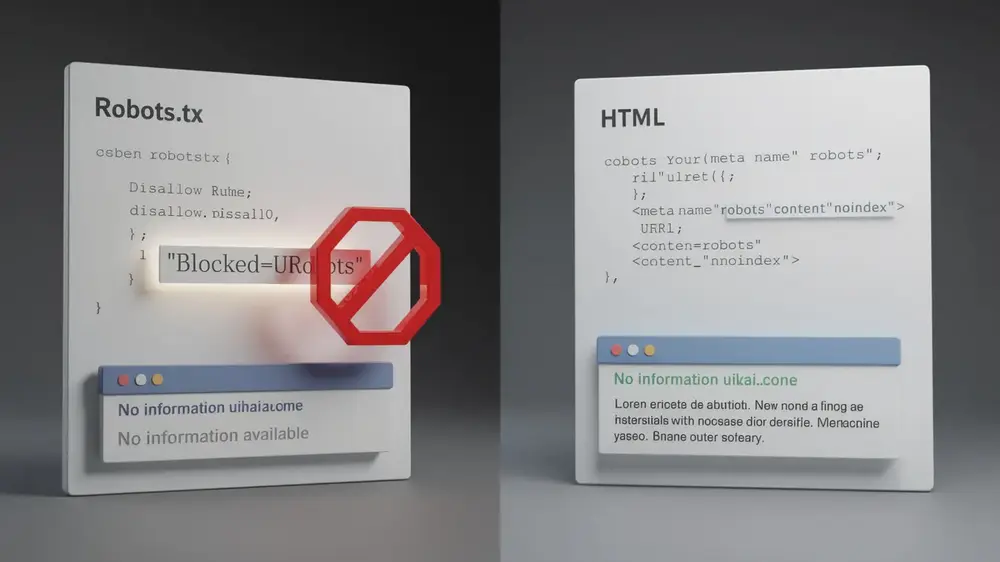
Critical Mistakes to Avoid When Using Noindex and Disallow
Combining these two directives incorrectly is one of the most damaging technical SEO errors a site owner can make. Never apply both noindex and disallow to the same page. When a crawler is blocked by robots.txt, it cannot access the page at all, which means it never reads the noindex instruction. The result is a page that remains potentially indexed in search results, often appearing as a vague entry with a “no information available” snippet.
A related misconception is assuming that disallow prevents indexing entirely. URLs blocked in robots.txt can still surface in search results if Google discovers them through external backlinks or XML sitemaps. Those listings appear without descriptions or cached content, which is rarely the outcome you want. This issue sometimes overlaps with managing duplicate content across your site, where unintended indexation creates redundant or low-quality SERP entries.
There are several other errors worth avoiding specifically:
- Using noindex in robots.txt: Google deprecated this method in 2019 and no longer supports it. Use page-level meta tags or X-Robots-Tag HTTP headers instead.
- Blocking CSS, JavaScript, or image files: Search engines need these resources to render pages correctly. Blocking them breaks rendering and directly harms rankings.
- Accidental noindex on high-value pages: CMS plugins and templates sometimes automatically apply noindex to categories, tags, or landing pages. Regular audits catch these before they erode organic traffic.
The most silent ranking losses often trace back to a misconfigured noindex or an overzealous disallow rule added months earlier and never reviewed. Treating these directives as set-and-forget configurations is a risk no site can afford to take lightly. Periodic audits in Google Search Console remain the most reliable safeguard against configuration drift. (Martha Vicher, mocobin.com)
Advanced Strategies and the Evergreen Value of Crawl and Index Control
Mastering noindex and disallow is not a skill you learn once and set aside. Crawl budget optimization and index quality control sit at the core of technical SEO fundamentals, and their importance holds steady regardless of how search algorithms evolve.
Google and major SEO authorities including Moz and Ahrefs consistently align on a clear division of responsibilities. Use noindex without disallow when your goal is to remove a page from search results. Use disallow exclusively for crawl control. Mixing the two when trying to exclude pages from search results is a well-documented mistake that can leave pages indexed despite your intentions.
For non-HTML content such as PDF files, meta tags are not an option. In these cases, implement noindex through X-Robots-Tag HTTP headers to maintain consistent index control across all content formats.
Advanced practitioners treat robots.txt and noindex as complementary tools rather than interchangeable ones. Robots.txt operates at the site-wide root level, while noindex functions at the individual page level. Combining both allows for granular crawl budget allocation and precise index management across large or complex sites.
The durability of these directives comes from their role in how search engines fundamentally operate. As long as crawlers exist and indexes require curation, webmasters will need reliable mechanisms to control what gets crawled and what appears in results. Future-proofing that control means running regular audits in Google Search Console to verify that noindex directives are honored, confirm robots.txt rules are working as intended, and catch configuration errors before they affect rankings or waste crawl budget.