URL parameters are a normal part of modern web architecture, especially on ecommerce sites, directories, marketplaces, booking platforms, and any website that uses filtering, sorting, pagination, tracking, or session-based functionality. The SEO risk begins when those useful URL variations create multiple crawlable addresses for the same or nearly identical content.
When parameter URLs are left unmanaged, they can create duplicate content signals, dilute canonical authority, waste crawl resources, and make it harder for search engines to identify the version of a page that should appear in search results. A strong parameter strategy is not about removing every parameter. It is about deciding which URL variations create real search value and which ones should remain functional for users but stay out of search engine indexing.
- URL parameters support useful site functions such as filters, sorting, pagination, tracking, and session handling, but they can create duplicate URLs when not controlled properly.
- Search engines may crawl many parameter variations that show the same content, which can reduce crawl efficiency and delay discovery of more important pages.
- Canonical tags, clean internal linking, consistent parameter order, noindex rules, and selective robots.txt controls each solve different problems and should not be treated as interchangeable fixes.
- The old Google Search Console URL Parameters Tool is no longer available, so teams should now rely on URL architecture, technical directives, log analysis, and Search Console monitoring.
- Some filtered URLs may deserve indexation when they match real search demand, while tracking IDs, session IDs, and minor sorting variations usually add no independent search value.
What Are URL Parameters and Why Do They Exist in Web Architecture
URL parameters are key-value pairs added to a web address after a question mark. A simple example is www.example.com/products?category=shoes&color=black&sort=price. In this URL, each item after the question mark gives the server or application extra instructions about what to display, how to arrange it, or how to track the visit.
Parameters are also called query strings or URI variables. They are widely used because they allow one page template to serve many different user needs. A product category page can be filtered by size, color, price range, brand, or availability. A blog archive can be sorted by date or popularity. A campaign URL can pass UTM tracking data to analytics tools without creating a separate static page.
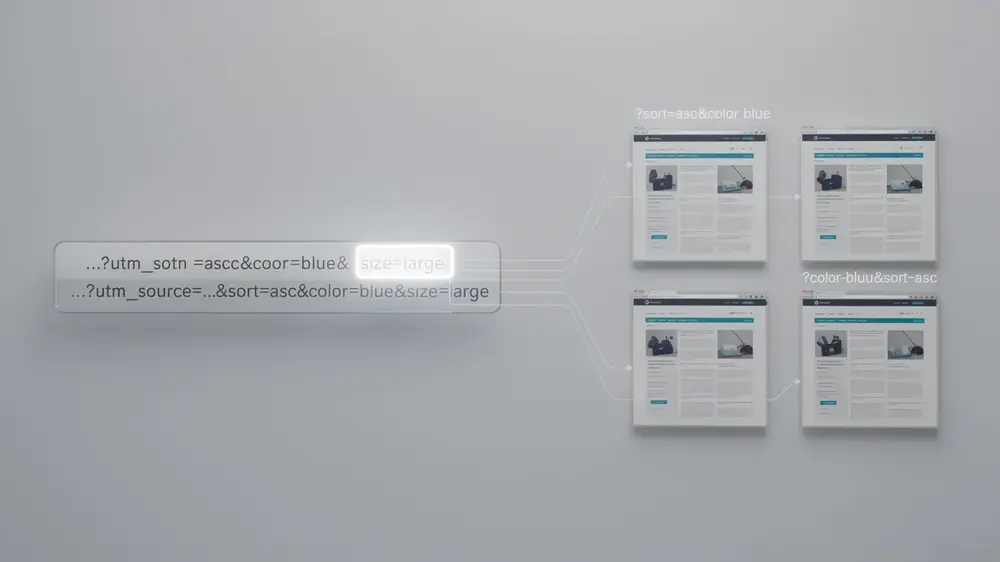
The SEO challenge is that search engines evaluate URLs as distinct addresses. For example, /products?color=black&sort=price and /products?sort=price&color=black may show the same product list, but the different parameter order can still produce separate crawlable URLs. When this happens across many filters and sorting options, a site can quickly create large numbers of near-duplicate pages. This is one reason parameter control is closely connected to duplicate content issues that affect crawl efficiency and indexing.
The practical starting point is to classify each parameter by its purpose. A parameter that changes the main content of a page may need different treatment from a parameter that only tracks a marketing campaign, sorts the same products, or stores a temporary session value. Without that classification, teams often apply broad rules that either block useful landing pages or allow too many low-value variations to be crawled.
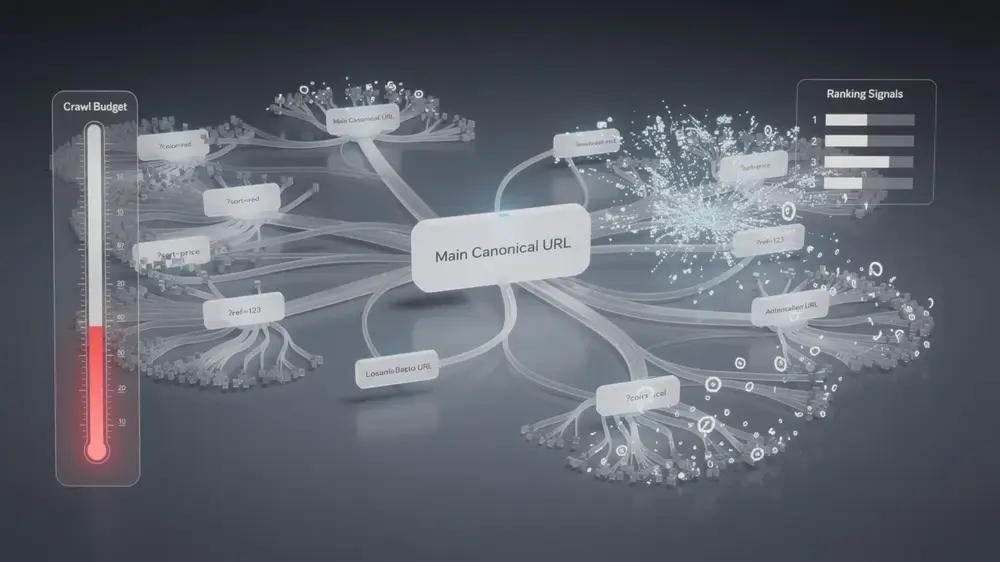
How URL Parameters Impact Crawl Budget, Duplicate Content, and Search Rankings
Mismanaged URL parameters usually create problems in layers. At first, the issue may look small: a few filtered URLs, a few tracking URLs, or several versions of the same category page. As filters, tags, sort options, and campaign parameters grow, those combinations can multiply into hundreds or thousands of URLs that do not provide unique search value.
Crawl efficiency is one of the first areas affected. Search engines do not crawl every URL on every site with the same frequency. When crawlers spend time discovering and revisiting parameter-generated duplicates, they may spend less time on pages that actually need attention, such as new articles, updated product pages, important category pages, or recently improved evergreen content.
Ranking signals can also become fragmented. If backlinks, internal links, or sitemap references point to multiple versions of the same content, search engines receive mixed signals about which URL is the preferred version. In this situation, canonical tags to consolidate duplicate URLs can help, but they work best when they are supported by consistent internal links, clean sitemap URLs, and a stable preferred URL structure.
Parameter order is another common source of duplication. URLs such as /products?color=red&size=large and /products?size=large&color=red may display identical results. If the site does not standardize the order, every filter combination can appear in several different forms. This can increase duplicate URL discovery and make reporting in crawl tools, server logs, and Google Search Console harder to interpret.
There is also a relevance problem. Some parameter URLs are useful for users but weak as search landing pages. A price sort, a temporary view preference, or a session ID usually does not create a page that deserves to rank. By contrast, a filtered category such as black running shoes or waterproof hiking jackets may reflect real search demand and deserve a clean, indexable URL. Good parameter SEO depends on knowing the difference.
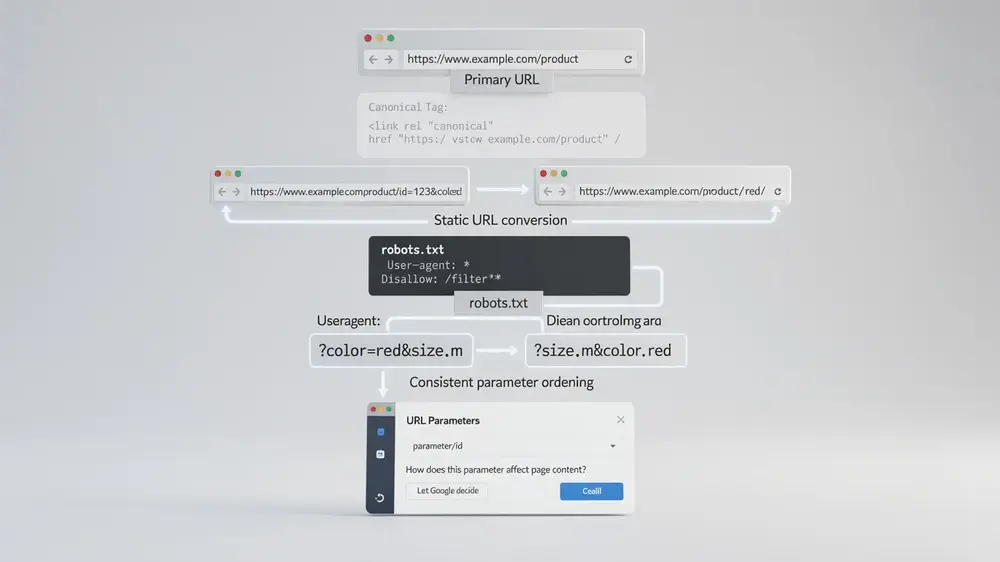
Strategic Methods for Managing URL Parameters to Optimize SEO Performance
Effective parameter management should be handled as a technical SEO system, not as a single setting. Canonical tags, noindex directives, robots.txt rules, clean URLs, and internal linking each have a separate role. Using the wrong method for the wrong purpose can create more problems than it solves.
Core Techniques Worth Applying
- Canonical tags: Use rel=”canonical” on duplicate or near-duplicate parameter pages when users can access the URL but search engines should consolidate ranking signals to a preferred version. Canonicals are signals, not guaranteed commands, so they should be supported by consistent internal links and sitemap URLs.
- Static URL conversion: Convert high-value parameter combinations into clean URLs when they represent real search demand. For example, www.example.com/products?category=widgets&color=purple may become www.example.com/widgets/purple if that filtered page has unique content, stable inventory, and meaningful search potential.
- Noindex decisions: Use noindex when a URL should remain accessible to users but should not appear in search results. Google must be able to crawl the page to see the noindex directive, so avoid blocking that same URL in robots.txt before the directive can be processed.
- Robots.txt controls: Use robots.txt best practices to reduce crawling of low-value URL patterns only after confirming that those URLs do not need to be indexed. Robots.txt is useful for crawl control, but it should not be used as the main method for canonicalization or guaranteed deindexing.
- Consistent parameter ordering: Standardize the sequence of parameters at the application level. This prevents equivalent URLs such as /products?color=red&size=large and /products?size=large&color=red from being generated as separate crawl paths.
- Google Search Console monitoring: Review Crawl Stats, Page Indexing, and URL Inspection data to identify parameter patterns that Google is crawling, excluding, or indexing unexpectedly. The former URL Parameters Tool is no longer available, so ongoing monitoring is now more important than manual parameter configuration inside Search Console.
A practical workflow is to group parameters into three categories: content-changing, display-changing, and tracking or technical. Content-changing parameters may deserve indexation when they create useful, stable pages. Display-changing parameters usually need canonical consolidation. Tracking and technical parameters should normally be excluded from search consideration through clean linking, canonical rules, noindex decisions, or crawl controls depending on the case.
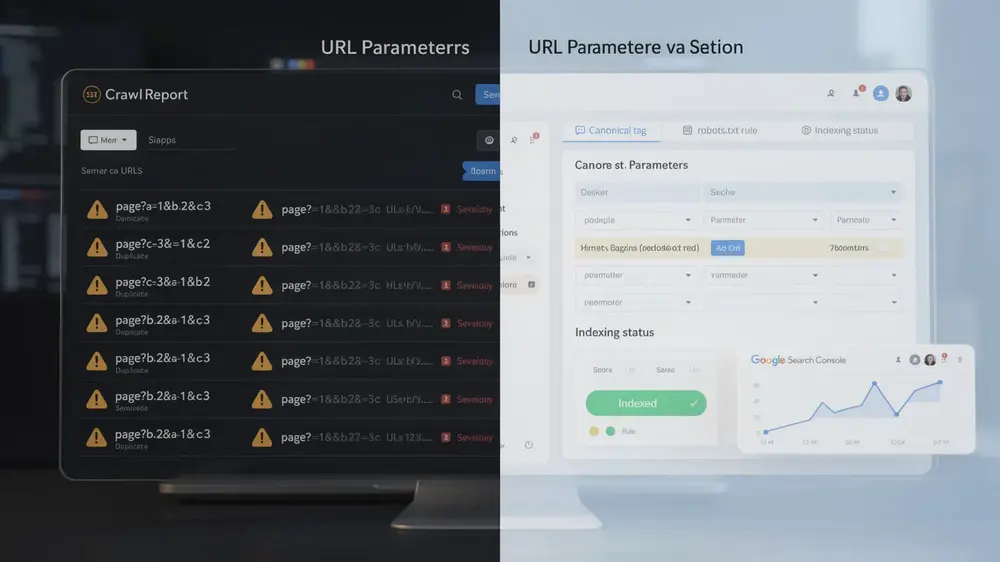
Critical URL Parameter Mistakes That Undermine SEO and How to Identify Them
URL parameter problems often stay hidden until crawl reports, index coverage data, or rankings begin to show unusual patterns. The most damaging mistakes usually come from applying one broad rule across every parameter type without checking whether the URL variation has search value, user value, or technical necessity.
One common mistake is blocking all parameters in robots.txt. This may reduce crawling, but it can also block filtered pages that could have performed well in search. A category filter with real demand, unique copy, useful inventory, and strong internal linking should not be treated the same way as a UTM tag or session parameter.
Another mistake is relying only on canonical tags. Canonicals are important, but they do not stop crawling. If a site generates thousands of parameter URLs and simply points them all back to one canonical URL, crawlers may still spend time discovering and processing those URLs. In larger sites, this can leave crawl budget management incomplete.
Teams also create problems when they combine robots.txt and noindex incorrectly. If a URL is blocked by robots.txt, Google may not be able to crawl the page and see the noindex tag. As a result, the blocked URL can still appear in search results if Google discovers it through links, although the page content itself may not be crawled. For URLs that must be removed from search results, noindex requires crawl access first.
Parameter order inconsistency is another issue that deserves more attention. A site may accidentally create many versions of the same page simply because different templates, plugins, or scripts output parameters in different sequences. This makes duplicate URL management harder and can also make analytics reports less reliable.
Finally, many teams do not check whether Google is following their intended signals. A canonical tag may exist, but Google may choose another canonical if internal links, redirects, sitemap entries, or page content send mixed signals. Parameter management should therefore include routine checks in Google Search Console, server logs, and crawl data rather than relying only on implementation assumptions.
Parameter SEO is strongest when every rule is verified against real crawl and indexation data. The goal is not just to write directives, but to confirm how search engines respond to them.

Advanced URL Parameter Strategies and the Evergreen Principles of Parameter SEO
Advanced parameter SEO starts with a simple principle: not every URL variation deserves the same treatment. Some parameter URLs are useful only inside the site experience. Others may represent strong organic search opportunities. The difference should be decided through data, not assumptions.
For ecommerce sites, marketplaces, and large directories, the most important question is whether a parameter combination creates a page that people would search for and find useful as a landing page. If the answer is yes, the page may deserve a clean URL, unique intro copy, relevant metadata, stable internal links, and inclusion in the sitemap. If the answer is no, the page should usually be consolidated, noindexed, or kept out of crawl paths depending on the situation.
This is where how URL structure affects SEO becomes more than a formatting issue. Clean URLs help users understand page context, make internal linking easier, and give search engines a clearer hierarchy. Parameter URLs can still function well for users, but important organic landing pages are usually easier to manage when they have stable, descriptive paths.
A useful decision framework looks like this:
- High-value filtered pages: Create clean, indexable URLs with unique content, stable inventory or listings, self-referencing canonical tags, and internal links from relevant category or hub pages.
- Moderate-value variations: Keep the pages accessible for users, but use canonical tags to consolidate signals to the preferred parent or clean URL.
- Low-value display options: Apply canonical tags or noindex rules when sorting, view changes, or minor refinements do not create independent search value.
- Tracking and session parameters: Avoid linking to these URLs internally, strip them where possible, and prevent them from becoming indexable landing pages.
- Known crawl traps: Use robots.txt carefully when a pattern creates endless crawl paths and does not need to be indexed, but verify that the rule does not block pages that require crawling for noindex or canonical processing.
Large sites should also standardize internal links. Navigation menus, faceted filters, breadcrumbs, pagination, XML sitemaps, canonical tags, and redirects should all point toward the same preferred URL logic. When different systems disagree, Google may choose a canonical version that does not match the site owner’s intention.
The long-term value of parameter management becomes clearer as a site grows. Every new filter, campaign, sorting option, plugin, or tracking system can create new URL patterns. A small issue on a ten-page site may become a serious crawl and indexation problem on a site with thousands of products, posts, or listings. The best approach is to document parameter rules early, review them regularly, and update them whenever site functionality changes.
- Google Search Central: URL Structure Best Practices
- Google Search Central: Designing a URL Structure for Ecommerce Sites
- Google Search Central: How to Specify a Canonical URL
- Google Search Central: Robots.txt Introduction and Guide
- Google Search Central: Block Search Indexing with noindex
- Google Search Central: URL Parameters Tool Deprecation Notice
- Search Engine Journal: Technical SEO Guide to URL Parameter Handling