Tag pages can either support a clear content taxonomy or quietly become one of the biggest sources of index bloat on a growing website. In WordPress and other CMS platforms, every new tag can create a separate archive URL, often without a clear editorial decision about whether that page deserves to appear in search results. For a small blog, this may look harmless. For a content-heavy website, unmanaged tags can produce hundreds of thin, overlapping archive pages that compete with categories, weaken crawl efficiency, and make site structure harder for both users and search engines to understand.
This guide explains how tag pages work, when they can support SEO, when they should be noindexed, and how to manage them through a practical taxonomy audit process.
- Tag pages are automatically generated archive URLs that may become indexable by default unless controlled through SEO settings, robots directives, or taxonomy rules.
- Noindex should be applied to thin, redundant, or low-value tag archives so that search engines can focus more efficiently on primary pages, category pages, and strong topic hubs.
- Tags and categories should serve different structural purposes. When a tag duplicates a category, it can create competing archive pages and weaken indexing clarity.
- A disciplined tag policy, such as limiting tags to 3 to 5 per post, merging synonyms, and removing single-post tags, helps prevent long-term taxonomy problems.
- 301 redirects, canonical tags, and noindex directives should be used based on the specific role of each tag page, not applied blindly across every archive.
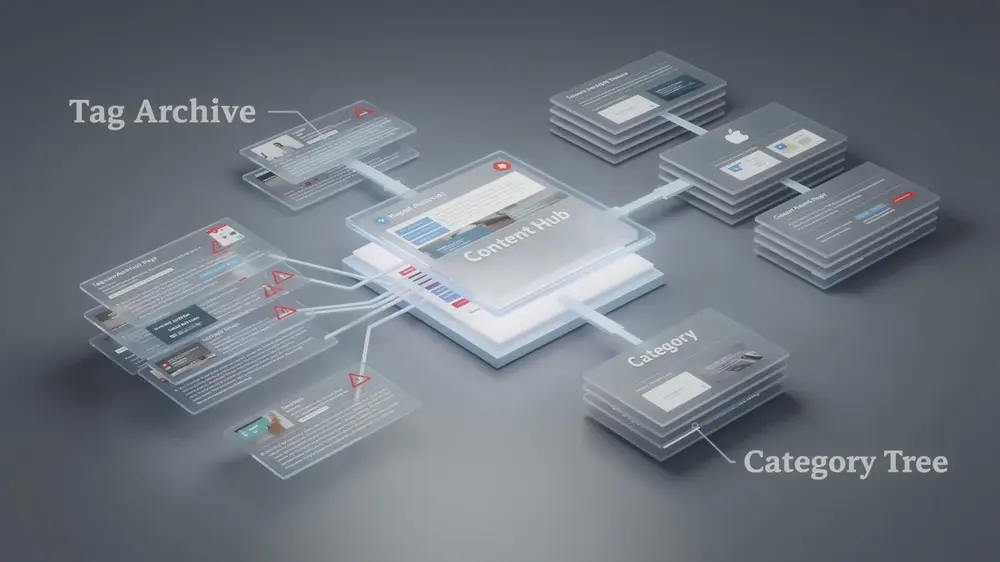
What Are Tag Pages and How Do They Function in Content Management Systems?
Tag pages are archive pages that a CMS creates when an editor applies a metadata label to a post. In WordPress, for example, adding a tag such as seo-tips can create a live archive URL at /tag/seo-tips/. That page then lists every post assigned to the same tag. The process is convenient because editors do not need to create the page manually, but this convenience is also why tag pages are often forgotten during SEO audits.
The difference between tags and categories is important. Categories are usually broad, hierarchical sections of a website. A category such as SEO may contain subcategories for technical SEO, content strategy, or link building. Tags are narrower and non-hierarchical. They point to specific ideas such as keyword research, crawl budget, backlinks, or on-page SEO. When used carefully, tags can support building topic clusters around precise subtopics without replacing the main category structure.
From a technical SEO perspective, each tag creates a separate URL that search engines may discover through internal links, archive navigation, XML sitemaps, or crawl paths inside the site. Unless the page is controlled with a robots directive, SEO plugin setting, or another indexing rule, search engines may treat it as a standalone page.
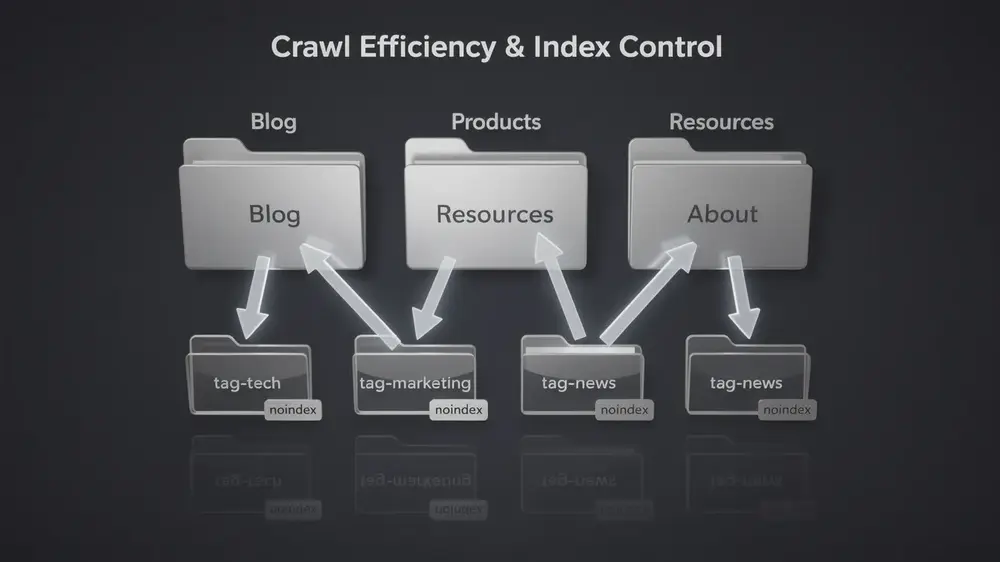
The issue is not that tag pages exist. The issue is that they often grow without governance. A site may begin with a few useful tags, then slowly accumulate variations such as technical-seo, technical seo, seo-technical, and crawl-optimization. If those pages list similar posts and contain no unique explanation, they add little value while increasing the number of URLs search engines need to evaluate.

Why Tag Pages Matter for Search Visibility and Site Architecture
Tag pages matter because they sit at the intersection of content organization, crawl management, and user navigation. A well-managed tag can help visitors move between related articles on a specific subtopic. A poorly managed tag can become another thin archive page that competes with categories, pillar pages, or other tag pages.
When tags are planned intentionally, they can support topical organization. For example, a website with many SEO articles may use a tag such as crawl budget to group technical guides, audit checklists, and case-based explanations around one narrow concept. If that archive has enough useful posts, a unique introduction, and a clear role in the internal linking structure, it can work as a focused content hub.
However, this benefit only appears when the tag page has a distinct purpose. If a tag archive repeats the same post list as a category page, it can create duplicate content issues and make it harder for search engines to identify the strongest URL for a topic. This is especially common on WordPress sites where editors add tags freely without a naming policy.
Tag pages also affect crawl efficiency. Search engines do not need to spend equal attention on every archive URL a CMS creates. If a site produces hundreds of low-value tag pages, those URLs can distract crawlers from more important pages, especially on larger websites with frequent publishing activity. This does not mean every tag page is harmful, but it does mean every tag page should have a reason to exist.
A useful tag system starts with a simple question: would this archive help a visitor find related content faster than a category page, internal search, or a pillar page? If the answer is no, the tag probably should not be indexed.

How to Optimize Tag Pages for Search Engines and Users
Tag page optimization works best when technical controls and editorial rules are handled together. A noindex setting can reduce search visibility problems, but it will not fix a messy taxonomy by itself. Likewise, a clean editorial policy helps prevent future issues, but existing archive URLs still need to be reviewed, consolidated, or improved.
The first step is deciding which tag pages deserve indexation. A tag archive with only one or two posts, no unique introduction, no search demand, and heavy overlap with a category page should usually be set to noindex, merged, redirected, or removed. A tag page should remain indexable only when it works as a distinct topic hub with enough related posts, useful explanatory copy, and a clear role within the site architecture.
Editorial discipline prevents the problem from growing again after cleanup. A practical standard is to limit tags to 3 to 5 per post, use categories for broad topics, and reserve tags for specific subtopics. Editors should avoid creating new tags for spelling variations, singular and plural duplicates, or temporary campaign labels that will not help users later.
When a tag page has no independent purpose and fully duplicates a stronger category page, a 301 redirect is usually the cleanest solution. When the tag page still has navigational value but should not compete in search, noindex may be more appropriate. Canonical tags are useful when similar archive pages need to signal a preferred URL, but they should not be used as a substitute for fixing a broken taxonomy.
Regular audits keep the system healthy. Export all tag archive URLs from the CMS or crawl tool, check which tags have only one post, compare tag archives against category archives, and review Google Search Console data for indexed tag URLs with no clicks or impressions. This process helps identify which tags should be improved, merged, redirected, or noindexed before the archive system becomes difficult to control.
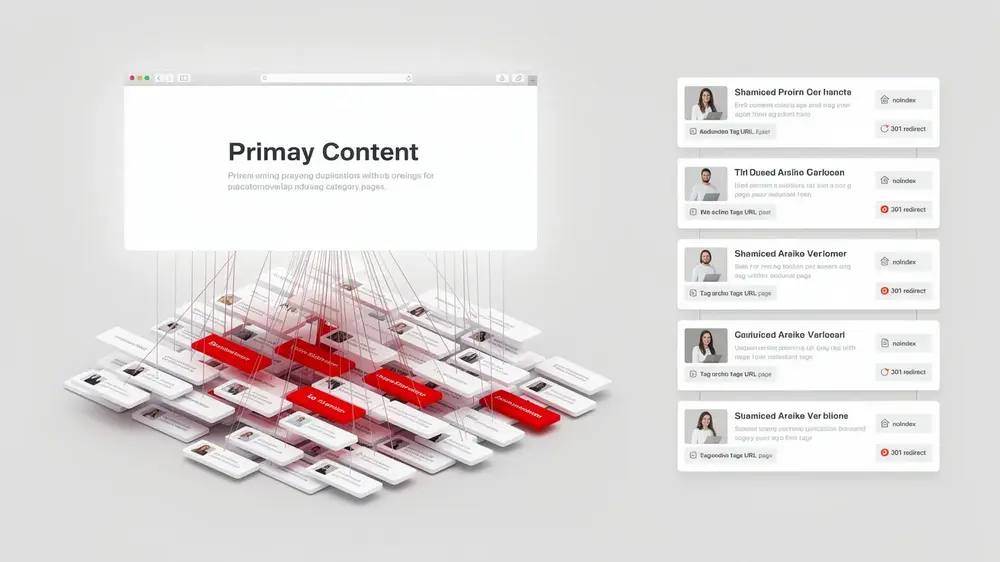
Critical Tag Page Mistakes That Harm SEO and How to Fix Them
One common mistake is assuming that adding more tags creates more ranking opportunities. In reality, a tag page only has SEO value when it provides a useful and distinct archive for a real topic. If the page is only a list of links with no unique explanation, no search demand, and no meaningful difference from other archives, it is unlikely to strengthen the site.
Over-tagging can also create long-term SEO debt. A few unnecessary tags may not seem serious at first, but hundreds of loosely defined labels can produce duplicate or near-duplicate URLs. This makes internal structure less clear and can contribute to keyword cannibalization problems when similar tag pages compete with each other or with stronger category pages.
A specific structural problem appears when tags mirror categories. For example, if a website has a category called Content Marketing and also creates a tag called content-marketing, both archive pages may list nearly the same posts. Search engines then need to decide which page is more representative, while users see two paths that do not offer a meaningful difference.
Another frequent mistake is leaving single-post tags indexed. A tag page with only one article rarely adds value because the archive page simply points back to the same post. In most cases, the better option is to remove the tag, merge it into a broader approved tag, or noindex the archive if it still has internal navigation value.
Fixing these issues requires a clear decision process rather than passive monitoring. The most effective actions include:
- Applying noindex directives to thin or redundant tag pages
- Redirecting tag pages that fully duplicate stronger categories or pillar pages
- Merging synonymous tags into one approved naming format
- Removing tags attached to only one post unless they have a clear editorial purpose
- Reviewing crawl data for excessive tag URL counts
- Checking Google Search Console for indexed tag pages with no meaningful performance
- Auditing cases where tag archives outrank the primary content they are meant to support
Tag systems rarely self-correct once editors have used them freely for years. The safest approach is to treat taxonomy management as scheduled SEO maintenance. A quarterly tag audit can prevent hundreds of low-value archive URLs from entering the index and protect the clarity of the site’s main content hierarchy.
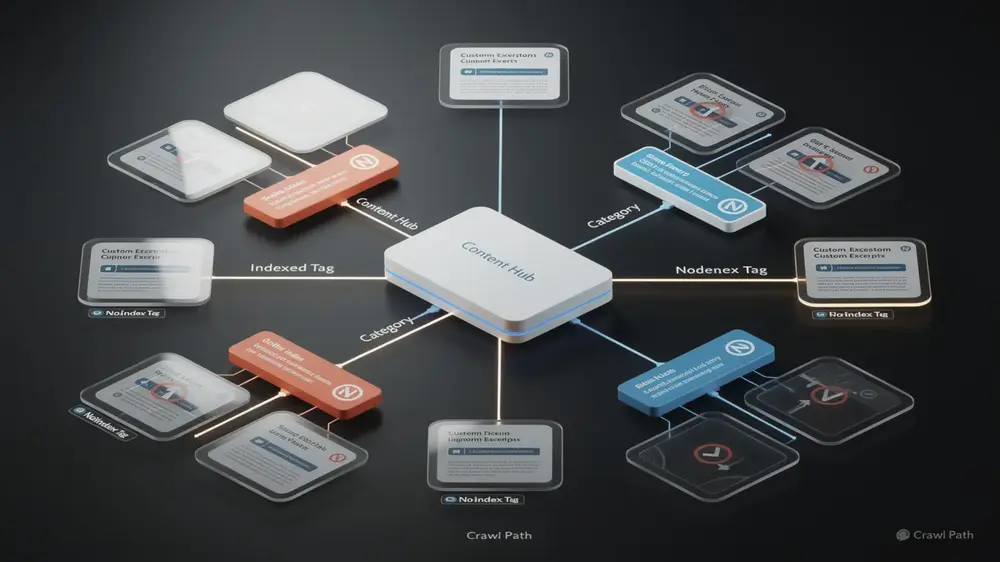
Advanced Tag Page Strategies and Evergreen SEO Principles
The strongest tag strategies treat tag pages primarily as navigation and taxonomy tools, not automatic ranking assets. Many websites benefit from applying noindex to most tag archives while keeping a small number of high-value tag pages indexable. The goal is not to remove tags completely, but to make sure search engines see the pages that truly help users and understand the site’s topical structure.
Index, Noindex, or Redirect: A Simple Decision Rule
Not every tag page should receive the same treatment. If a tag contains only one post, has no search demand, and duplicates a category archive, it should usually be removed, merged, redirected, or noindexed. If a tag groups several strong articles around a specific subtopic and includes unique explanatory content, it may deserve indexation as a focused topic hub.
A practical decision rule can be summarized as follows: use noindex when the tag is useful for users but weak for search, use a 301 redirect when the tag has no independent purpose and overlaps with a stronger URL, and keep the tag indexable only when it provides a clear topic hub that is different from existing categories and pillar pages.
Differentiating Tag Archives Through Content Quality
A tag page that deserves indexation should not rely only on automated post snippets. It should include a short, unique introduction that explains the topic, clarifies what kind of content the archive contains, and helps users decide where to go next. This copy does not need to be long, but it should be written for the specific tag rather than copied from a category page.
For example, a tag archive for crawl budget could explain when crawl budget matters, which types of websites should monitor it, and how the listed articles help users audit crawl efficiency. That creates a stronger page than a simple list of posts with repeated excerpts.
Practical Example: When a Tag Page Should Be Removed
Consider a site with both a category page for Technical SEO and separate tags for technical-seo, technical seo, seo technical, and crawl optimization. If each tag page lists nearly the same articles and none of them includes unique explanatory content, the site is not creating stronger topical authority. It is creating competing archive URLs.
In this case, the best approach is to keep the strongest category page, merge duplicate tags, redirect redundant tag URLs where appropriate, and noindex any remaining tag archives that exist only for user navigation. This improves structure without removing useful internal browsing paths.
Governance as a Long-Term SEO Principle
The underlying principle is consistent across algorithm updates: controlled taxonomy helps search engines understand what matters most on a website. A clear content hierarchy reduces unnecessary URL duplication, supports better crawling, and makes internal linking strategy easier to manage.
Future-proofing a tag strategy requires written editorial guidelines, scheduled taxonomy audits, and a consistent naming system. Tags should support the site’s structure, not expand every time an editor wants to describe a post in a slightly different way.
Tag Page Audit Checklist
A tag audit does not need to be complicated, but it should be systematic. Use the following checklist when reviewing existing tag archives:
- Export all tag archive URLs from your CMS, crawl tool, or SEO plugin.
- Identify tags attached to only one post.
- Find duplicate naming patterns, including spelling variations, plural forms, and hyphen differences.
- Compare tag archives against category archives to detect overlapping post lists.
- Review whether each indexable tag page has unique introductory copy and a clear user purpose.
- Check Google Search Console for indexed tag URLs with no clicks, impressions, or meaningful search visibility.
- Decide whether each tag should be kept indexable, noindexed, redirected, merged, or removed.
- Document approved tag naming rules so future editors do not recreate the same problem.
For growing content sites, this review should be repeated regularly. A quarterly audit is usually enough for small and mid-sized sites, while large publishers may need monthly taxonomy checks if many editors are creating new content.
Practical SEO note: Most tag pages should not be indexed by default. They should earn indexation only when they provide a distinct topic hub, contain enough related posts, include useful explanatory content, and support a clearer path for users. For many WordPress sites, categories should remain the primary method of organizing content, while tags should be used carefully for narrower connections between related posts.
- Google Search Central: Creating Helpful, Reliable, People-First Content
- Google Search Central: Robots Meta Tags and X-Robots-Tag
- Google Search Central: How to Specify a Canonical URL
- Tag Pages & Content Tagging For SEO: A Complete Guide
- Tagging Blog Posts: Do Blog Tags Help SEO?
- How To Create Content Tagging Policies For News Publishers
- Do Blog Tags Affect SEO at All Anymore? – Moz
- Should I Allow Blog Tag Pages to be Indexed? – Moz