Index bloat occurs when search engines index large volumes of low-value pages, consuming crawl budget that would otherwise support a site’s most important content. For site owners and SEO practitioners, understanding how bloat forms and how to address it systematically is a practical necessity, not an optional refinement.
- Index bloat drains crawl budget by filling it with parameter pages, tag archives, filtered listings, and thin content that offer minimal value to users.
- Multiple similar pages competing for the same keywords split ranking signals, preventing any single page from building the authority needed to rank well.
- Robots.txt and noindex tags serve different functions and must not be used interchangeably, as misapplication can leave unwanted pages visible in search results.
- Removing bloated pages without 301 redirects discards accumulated link equity, making proper consolidation a required step rather than an optional one.
- Long-term index health depends on CMS-level configuration and scheduled audits, since reactive fixes alone will not prevent new bloat from regenerating as a site grows.

What Is Index Bloat and Why Does It Occur in Search Engines
Index bloat is the condition where search engines index large volumes of pages that provide minimal value to users. These pages include filtered product listings, paginated content, parameter-driven URLs, tag archives, and thin content pages that offer little beyond what already exists elsewhere on the site. The result is a bloated index that works against the site rather than for it.
The Mechanics of How Search Engines Allocate Crawl Budget
Search engines assign a limited crawl budget to each domain, meaning bots can only visit a finite number of pages within a given timeframe. When that budget is consumed by low-value pages, crawlers cannot efficiently discover and rank the content that actually matters. New cornerstone pages may go unindexed for longer periods, and existing important pages may receive less frequent recrawling. Index bloat directly affects three areas: crawl budget efficiency, site authority distribution, and the speed at which significant pages get discovered.
Common Sources of Low-Value Pages That Cause Index Bloat
Modern content management systems and e-commerce platforms are a primary driver. Filters, sorting options, search parameters, and taxonomies automatically generate numerous URL variations without proper indexing controls in place. A single product category can produce dozens of indexable URLs that are functionally near-identical. This connects closely to duplicate content issues in SEO, where fragmented signals weaken overall site authority.
The key diagnostic challenge is distinguishing page variations that genuinely serve users from redundant URLs that only dilute SEO signals. Not every generated URL is a problem, but many are.

How Index Bloat Damages Your SEO Performance and Site Authority
Index bloat rarely causes a single isolated problem. Instead, it triggers a chain of interconnected SEO issues that compound over time, affecting crawl efficiency, ranking strength, and how search engines perceive your domain as a whole.
The Relationship Between Index Bloat and Crawl Budget Efficiency
Search engine bots allocate a limited crawl budget to each site. When that budget is consumed by low-value or duplicate pages, bots spend less time on the cornerstone content that actually drives business results. New pages and important updates take significantly longer to be indexed as a consequence, which directly delays time-to-ranking for fresh offerings. Configuring your robots.txt file to manage crawler access is one practical way to steer bots toward your most valuable content and away from bloated sections of your site.
How Bloated Indexes Fragment Ranking Signals Across Similar Pages
Keyword cannibalization is a direct byproduct of index bloat. When multiple similar pages compete for the same search terms, ranking signals become diluted and internal linking equity gets split across several URLs instead of concentrating on one authoritative page. No single page builds the strength needed to rank well.
Beyond cannibalization, low-quality indexed pages weaken overall site authority. Search engines evaluate the quality ratio of a domain’s indexed content, and a high proportion of thin or redundant pages leads them to deprioritize crawling and ranking across the entire site, including genuinely valuable pages. When bloated pages surface in search results, click-through rates and engagement metrics also suffer, sending negative user experience signals that search engines actively monitor.
The compounding nature of index bloat is what makes it easy to underestimate. Each individual thin page may seem harmless, but collectively they reshape how search engines perceive the entire domain’s quality. Addressing the root causes in CMS configuration, rather than cleaning up symptoms page by page, tends to produce more durable results. — Martha Vicher

Complete Checklist to Audit and Fix Index Bloat Issues
How to Conduct an Index Bloat Audit Using Search Console and Crawlers
The first step is exporting all indexed pages from Google Search Console, then running a site crawler alongside that data to identify which page types are contributing to bloat. Once you have a full picture, categorize the sources: parameter pages, filtered navigation, tag archives, paginated content, and thin or duplicate content each require a slightly different fix. Grouping them by type makes the remediation process far more manageable.
After categorization, use the Google Search Console URL Parameter Tool to tell search engines which parameters generate genuinely different content and which only change sorting or display order without adding unique value. This step alone can significantly reduce unnecessary crawling of parameter-driven variations.
Technical Implementation Methods: Robots.txt, NoIndex, and Canonical Tags
Update your robots.txt file first to block problematic sections such as filtered navigation paths and internal search result pages. This prevents new bloat from accumulating before you address pages already indexed. For pages that must stay live for users but should not appear in search results, apply meta robots noindex tags. This gives more precise control than robots.txt for content like tag archives, author pages with minimal content, and parameter variations.
For duplicate or near-duplicate content, canonical tags for managing duplicate content consolidate authority back to the preferred version, whether that is the primary page in a paginated series or the clean URL without parameters.
Finally, execute content pruning by classifying pages through a thorough audit, removing genuinely low-value pages with 301 redirects to preserve link equity, and consolidating thin pages into stronger resources. Track crawl requests in Search Console logs over time to confirm that low-value URLs are receiving less attention from search engines after your fixes are in place.

Critical Mistakes to Avoid When Fixing Index Bloat
The Difference Between Robots.txt Blocking and NoIndex Implementation
One of the most common technical errors is treating robots.txt disallow and noindex meta tags as interchangeable. They serve distinct purposes. Robots.txt prevents crawling entirely, meaning Googlebot will not fetch the page at all. A noindex directive, by contrast, requires the page to be crawled before the instruction can be read and acted upon. Using robots.txt to block a page you actually want deindexed can backfire, since search engines may still index URLs they discover through internal or external links, even without crawling the content itself.
Blocking pages with robots.txt while leaving internal links pointing to those pages compounds the problem. Google can index a URL based on link discovery alone, leaving the page visible in search results with little to no content shown.
How to Properly Remove or Consolidate Pages Without Losing Link Equity
Removing pages without 301 redirects is a costly oversight. Lost link equity, broken user experiences, and wasted accumulated SEO value are the direct consequences. This issue shares structural similarities with keyword cannibalization problems, where poor URL management dilutes the authority that should be concentrated on fewer, stronger pages.
Fixing existing bloated pages without updating CMS settings, template configurations, or URL generation rules only provides temporary relief. New content will regenerate the same bloat patterns. Ongoing monitoring of indexed page counts, crawl budget consumption, and CMS configurations is necessary to prevent gradual recurrence as the site grows.
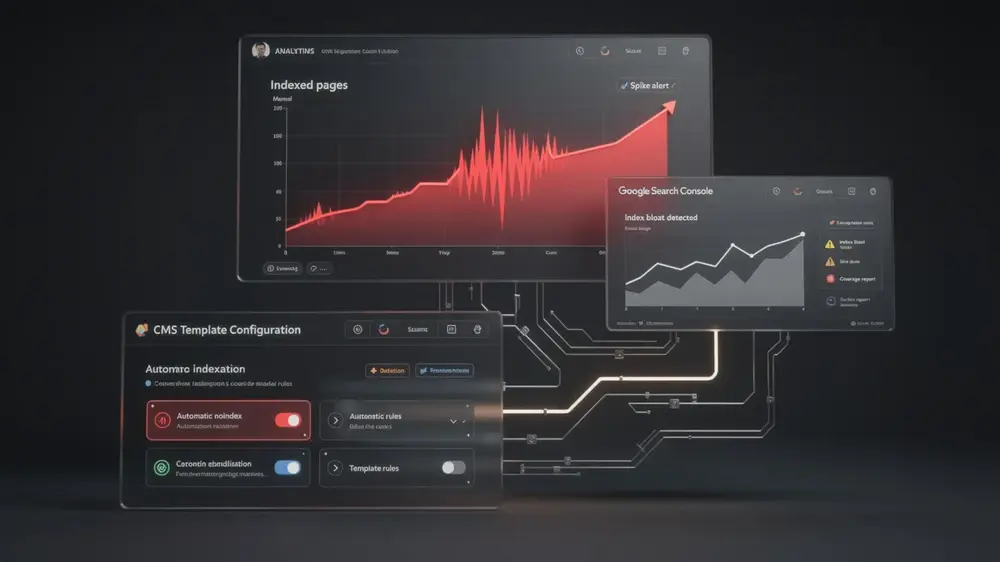
Advanced Strategies and Long-Term Index Health Maintenance
Setting Up Ongoing Monitoring Systems to Prevent Index Bloat Recurrence
Reactive fixes only go so far. Sustainable index health depends on monitoring systems that catch problems early, before they consume significant crawl budget allocation and drag down overall site quality signals. Tracking indexed page counts over time gives you a baseline, so unusual spikes in indexed URLs become immediately visible. Setting up alerts for those spikes, combined with regular reviews of Google Search Console coverage reports, lets you identify new sources of bloat before they scale into a serious remediation project.
Server log analysis adds another layer of precision. By examining which bloated page types receive the most bot traffic, you can prioritize fixes that deliver the greatest impact first, rather than working through a long list in arbitrary order.
Proactive CMS Configuration to Prevent Bloat Generation at the Source
Prevention is considerably more efficient than remediation. Configuring your CMS or e-commerce platform at the template level, so that appropriate indexing directives apply automatically on publication, removes the need to constantly clean up after new content goes live.
Quarterly technical SEO audits are worth scheduling as a standing task, especially for large sites. Platform updates and new plugins frequently introduce URL generation patterns that were not present before, and those patterns can quietly produce bloat at scale. Catching them early keeps the problem manageable.
Index quality management is an evergreen SEO fundamental. Search engines continuously refine how they evaluate site quality and allocate crawl resources, so the underlying principles here remain relevant regardless of specific algorithm changes.