Index bloat is a technical SEO condition where search engines accumulate excessive low-value or redundant pages from a site, reducing the efficiency with which crawl budget is spent and weakening the quality signals that influence rankings. Left unaddressed, the problem compounds over time, affecting not only how quickly new content is discovered but also how search engines assess the overall authority of a site.
- More indexed pages do not produce better rankings. A smaller set of high-value pages consistently outperforms a large index filled with thin or duplicate content.
- Index bloat consumes crawl budget on low-value URLs, which delays the discovery and ranking of your most important pages.
- Noindex tags, robots.txt directives, canonical tags, and focused XML sitemaps each serve a distinct role in controlling what search engines store and evaluate.
- Platforms like WordPress and e-commerce sites with faceted navigation can generate bloat automatically through default settings, making regular audits necessary rather than optional.
- Treating index bloat as a one-time fix rather than an ongoing governance issue allows the problem to rebuild quietly through new content types, CMS updates, or site feature additions.

Understanding Index Bloat: Definition and Fundamental Concepts
Index bloat occurs when search engines index excessive low-value, redundant, or thin-content pages from a website. The result is a diluted quality signal that makes it harder for search engines to identify which pages genuinely deserve attention and ranking consideration.
A common misconception is that more indexed pages always means better visibility. The reality is the opposite. A site with 10,000 low-value pages consistently performs worse than a site with 1,000 well-crafted, high-value pages. The condition is not about volume; it is about the proportion of pages that actually serve users.
A useful way to picture this is a library where most shelves are filled with empty books or duplicates. Staff spend time cataloguing those books instead of helping visitors find genuinely useful titles. Search engines face the same problem. They must allocate limited resources to crawl and process the web, and pages that offer minimal user value consume those resources without delivering proportional ranking benefits. This directly affects how crawl budget is allocated across your site, which can delay the discovery of your most important content.
At its core, index bloat represents a mismatch between what gets indexed and what should be indexed. Irrelevant, duplicate, or thin pages create inefficiency in how search engines evaluate a site. Resolving that mismatch is the starting point for any serious technical SEO audit.
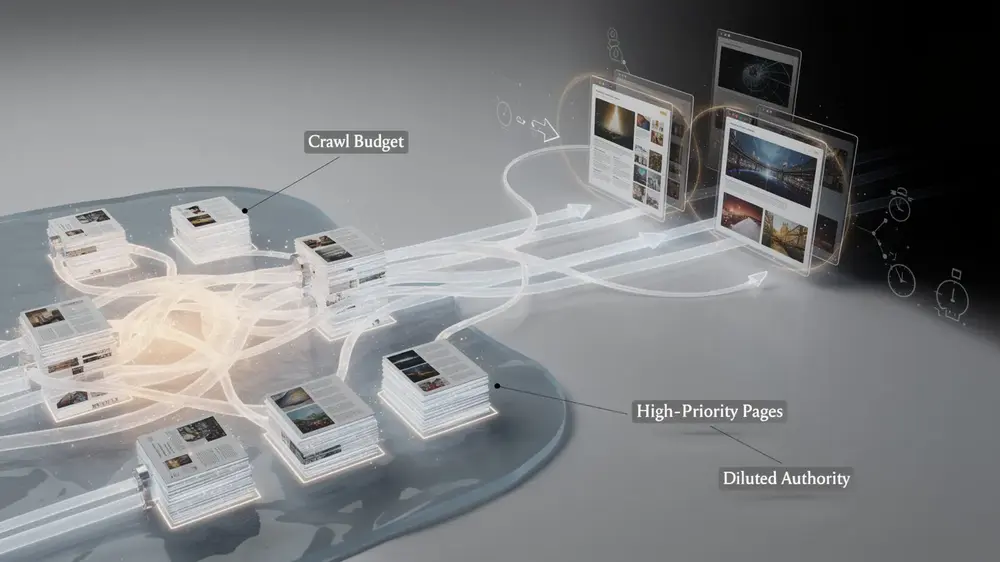
Why Index Bloat Matters: Impact on Crawl Budget, Rankings, and Site Authority
Index bloat is one of the more damaging technical SEO problems a site can develop, and its effects compound over time. At its core, the issue is about resource allocation. Search engine bots operate within a crawl budget, meaning they allocate a limited number of crawls to any given site within a set timeframe. When a site is filled with low-value pages, those bots spend their budget on content that contributes nothing, leaving important pages crawled less frequently or not at all.
The consequences reach beyond crawl efficiency. Excessive low-value pages send a diluted quality signal to search engines, making it harder for them to identify which content genuinely deserves to rank. This is closely connected to problems like duplicate content and its effect on search rankings, where similar or thin pages compete against each other and weaken overall site authority.
Delayed indexing is another practical consequence. When crawl budget is consumed by bloated pages, new or updated content takes longer to appear in search results, which directly weakens rankings for priority pages. Beyond rankings, unnecessary bot activity increases server load, and irrelevant pages surfacing in search results create a poor user experience.
Addressing index bloat improves crawl efficiency, protects authority signals, and ensures search engines concentrate their attention on the content that matters most to your site’s visibility.
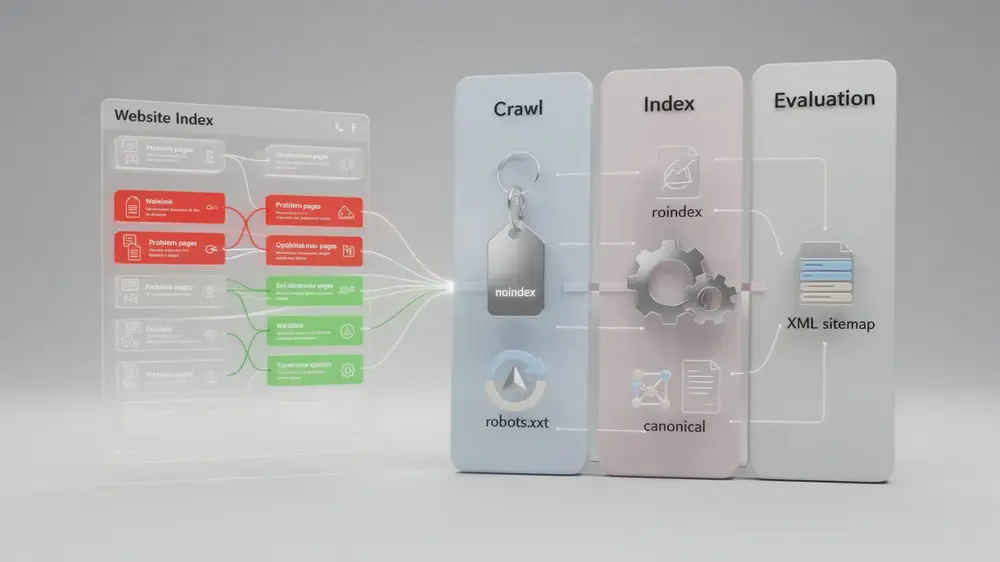
Diagnosing and Resolving Index Bloat: A Practical Optimization Roadmap
The starting point for any bloat audit is Google Search Console. Compare the number of pages Google has indexed against the number of pages you actually consider valuable. A significant gap between those two figures is a reliable signal that bloat is present and worth addressing.
From there, the management process maps onto three phases of how search engines operate. During the crawl phase, the goal is identifying which URLs are problematic. During the index phase, the focus shifts to preventing low-value pages from being stored. During the evaluation phase, the work involves strengthening quality signals so that the pages you do want indexed are treated as authoritative.
Each phase calls for specific technical controls. thin and low-value content is often best handled with noindex meta tags, which allow crawling but prevent indexing. Pages you want search engines to ignore entirely should be blocked via robots.txt. Canonical tags work well for duplicate or near-duplicate content variations. Alongside these, submit focused XML sitemaps that list only your high-priority pages, giving search engines a clear signal about where to concentrate their attention.
One point worth emphasizing is that bloat is not a one-time problem. New low-value pages can appear through faceted navigation, auto-generated content, or CMS updates. Establishing a regular audit schedule keeps the issue from quietly rebuilding over time.
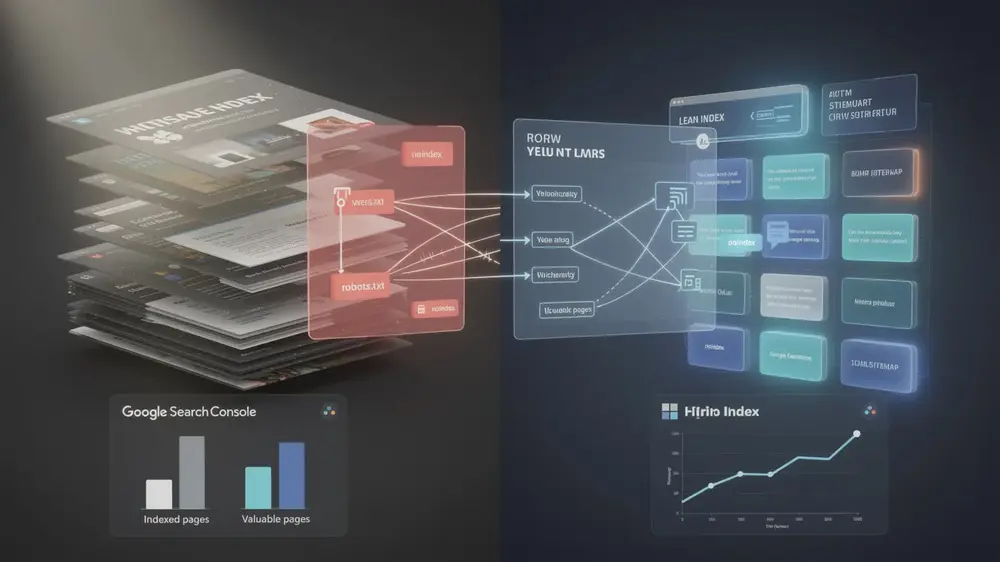
Diagnosing and Resolving Index Bloat: A Practical Optimization Roadmap
The starting point for any bloat audit is Google Search Console. Compare the number of pages Google has indexed against the number of pages you actually consider valuable. A significant gap between those two figures is a reliable signal that bloat is present and worth addressing.
From there, the management process maps onto three phases of how search engines operate. During the crawl phase, the goal is identifying which URLs are problematic. During the index phase, the focus shifts to preventing low-value pages from being stored. During the evaluation phase, the work involves strengthening quality signals so that the pages you do want indexed are treated as authoritative.
Each phase calls for specific technical controls. thin and low-value content is often best handled with noindex meta tags, which allow crawling but prevent indexing. Pages you want search engines to ignore entirely should be blocked via robots.txt. Canonical tags work well for duplicate or near-duplicate content variations. Alongside these, submit focused XML sitemaps that list only your high-priority pages, giving search engines a clear signal about where to concentrate their attention.
One point worth emphasizing is that bloat is not a one-time problem. New low-value pages can appear through faceted navigation, auto-generated content, or CMS updates. Establishing a regular audit schedule keeps the issue from quietly rebuilding over time.

Critical Index Bloat Mistakes and How to Avoid Them
One of the most persistent misconceptions in SEO is that a larger index automatically produces better rankings. The reality is the opposite. Excessive low-value pages dilute crawl budget, fragment link equity, and signal poor content quality to search engines. Quantity without quality actively harms performance rather than supporting it.
E-commerce sites carry particular risk here. Uncontrolled faceted navigation systems can generate thousands of filter combinations, each producing a distinct URL that search engines may attempt to crawl and index. Without proper controls, a single product catalog can balloon into tens of thousands of near-identical pages overnight.
Platform defaults compound the problem. WordPress, for example, creates thin duplicate content through pagination, tag archives, category pages, and author archives by default. Many site owners are unaware these pages exist in their index at all until they audit it directly.
Incomplete technical fixes are another common failure point. Adding noindex tags without monitoring Google Search Console to confirm deindexing leaves the problem unresolved. Similarly, blocking URLs in robots.txt best practices that are already indexed does not remove them from the index and can actually prevent Google from reading the noindex directive on those pages.
Perhaps the most damaging mistake is treating index bloat as a one-time technical fix rather than a symptom of broader content strategy gaps. If the underlying processes that generate low-value pages remain unchanged, bloat will return regardless of how thoroughly the current cleanup is executed.
From an editorial perspective, the distinction between a technical fix and a strategic correction is where most index bloat remediation efforts fall short. Cleaning up existing low-value pages without addressing the workflows and platform defaults that produced them is a temporary measure, not a durable solution. Sustainable index health requires both the technical controls and the content governance to back them up.
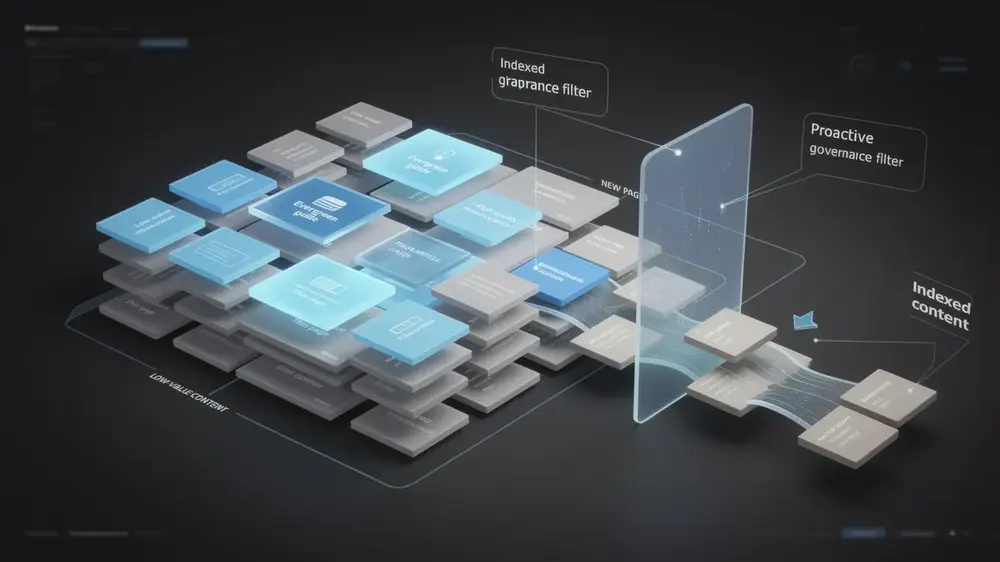
Advanced Index Bloat Management and Evergreen Principles
Index bloat management is not a periodic cleanup task. It reflects a fundamental truth about how search engines allocate finite resources. Crawl budget and indexing capacity will always be limited, and search engines will always favor sites that use those resources efficiently. That constraint does not disappear as technology improves.
The core principle at work here is that search engines consistently prioritize quality signals over sheer quantity. This holds true across algorithm updates, ranking factor shifts, and changes in how content is evaluated. Advanced SEO practitioners treat this as a stable foundation rather than a trend to chase.
One of the most practical shifts in mindset is moving prevention upstream. Every new page type, content category, or site feature should be evaluated for indexation value before it goes live, not after problems appear. Pairing that habit with tools like canonical tags for managing duplicate and near-duplicate content gives teams a scalable way to control what search engines see as your site grows.
Scalable index health also requires governance, not just one-time audits. Establishing clear rules for what gets indexed as a site expands prevents technical debt from accumulating quietly over time. Site architecture decisions directly shape index health, so systematic policies matter more than reactive fixes.
As search engines grow more capable of identifying low-value content, the cost of neglecting index bloat is likely to increase. Proactive management is becoming less optional and more central to maintaining competitive search visibility over the long term.