Pagination SEO helps search engines discover, crawl, and evaluate content that is divided across multiple sequential URLs. It is especially important for websites with product categories, blog archives, resource libraries, search result pages, or any section where hundreds of items cannot load efficiently on one page. When pagination is implemented without a clear crawl path, deeper content may receive weak internal link signals, appear inconsistently in search results, or remain undiscovered for important long-tail queries.
- Paginated URLs should remain crawlable when they are part of the main discovery path for products, articles, or category items.
- Each paginated page should use a stable URL pattern and clear HTML links so search engines can move through the sequence without relying only on JavaScript.
- Self-referencing canonical tags are usually the safest default for paginated pages because page 2, page 3, and deeper pages often contain different items from page 1.
- Metadata can include page numbers or contextual modifiers when it improves clarity, but artificial title variations are not always necessary for every paginated URL.
- Large sites should support pagination with contextual internal links, XML sitemaps, crawl audits, and Search Console checks to reduce the risk of hidden indexation gaps.

What Is Pagination and Why Does It Exist in SEO?
Pagination is the practice of splitting a large group of items into separate pages with unique URLs. A product category might use /category/page/2/, a blog archive might use ?paged=2, and a search result page might use a parameter such as ?page=3. Users move through the set with numbered links, Previous buttons, Next buttons, or Load More patterns that update the URL.
From a site architecture perspective, pagination solves a practical problem. Loading hundreds of products, posts, or listings on a single page can slow performance, weaken mobile usability, and make the page difficult to scan. Splitting the set into smaller pages improves speed and usability while keeping the full collection available.
The SEO challenge is that search engines still need a reliable way to reach every important item in the sequence. If page 1 is the only strongly linked URL and deeper pages are hard to crawl, older articles or lower-positioned products can become difficult for bots to discover. This is where pagination moves from a design choice to a technical SEO issue.
Pagination can also create quality and duplication concerns when every page uses the same title tag, meta description, introduction, and template text. Similar layouts are normal in paginated sets, but unclear signals can make it harder for search engines to understand which URLs deserve independent visibility. A good pagination setup reduces unnecessary duplicate content concerns without hiding useful pages from crawlers.
Pagination appears most often in e-commerce categories, blog archives, news sections, resource hubs, forum threads, review lists, and internal search pages. In each case, the goal is the same: keep the user experience manageable while preserving a clear discovery path for search engines.
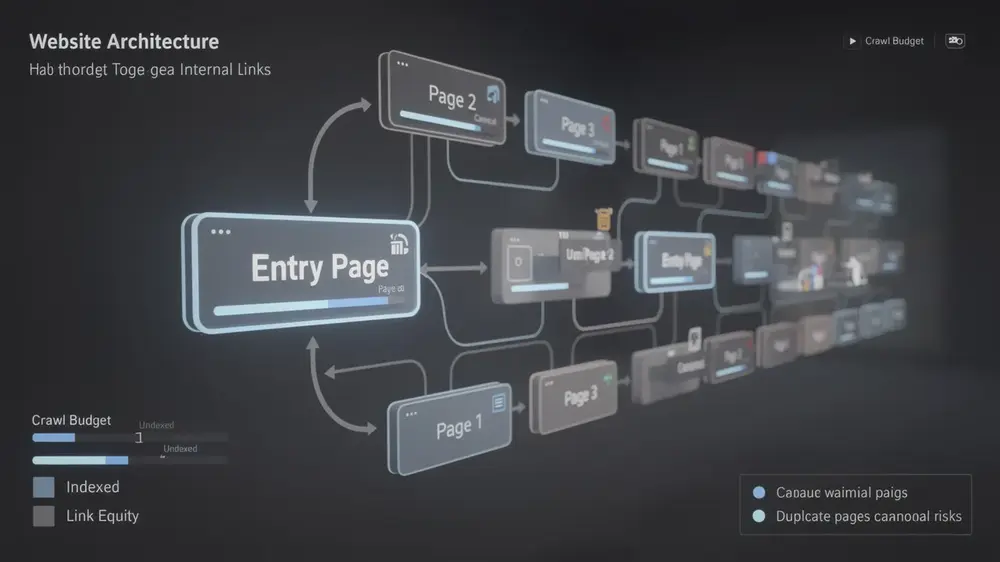
How Pagination Impacts Crawling, Indexing, and Ranking Performance
Pagination affects more than navigation. It influences how search engines move through a site, how internal link signals reach deeper content, and whether valuable pages appear in the index at all. For small websites, pagination problems may have a limited impact. For large archives or product catalogs, the same problems can quietly affect hundreds or thousands of URLs.
Crawl Budget and Internal Link Equity
Well-structured pagination gives crawlers a simple route from the first page of a category to the deeper parts of the same set. The best setups use crawlable HTML anchor links, stable URL patterns, and a logical page sequence. This helps search engines move through the list without hitting dead ends, duplicate parameter traps, or JavaScript-only paths.
Internal link equity also matters. A category page may receive strong authority from the main menu, homepage, breadcrumbs, or related pages. If that authority flows only to page 1, the deeper content receives weaker signals. A crawlable sequence allows some value to pass from page 1 to page 2, page 3, and beyond. For important items buried deep in the set, additional contextual links can provide an even stronger discovery path.
Indexing Gaps and Duplicate Content Risks
When crawlers cannot reach deeper paginated URLs, the content on those pages may be discovered slowly or missed completely. This is common when pagination links are hidden behind scripts, blocked by robots rules, or replaced by infinite scroll without real linked URLs. In practice, the lost visibility often affects long-tail searches: older articles, niche product pages, filtered collections, or low-volume topics that still bring qualified visitors.
Duplicate metadata and repeated template text can also weaken clarity. Search engines usually understand that paginated pages share a similar layout, but that does not mean every signal should be ignored. A clean URL structure, crawlable links, and sensible canonical tag implementation help search engines understand whether each paginated page should stand on its own or point to a broader consolidated version.
User experience plays a supporting role as well. If users can move through a category quickly, return to previous pages easily, and reach relevant items without frustration, the page set is more likely to support engagement. Pagination should help both users and crawlers, not force one experience at the expense of the other.
Technical Implementation Roadmap for Pagination SEO
A reliable pagination setup starts with one principle: every important page in the sequence should be reachable through a crawlable path. Design, JavaScript, and performance choices can vary by website, but the underlying URLs and links should remain clear enough for search engines to follow.
URL Structure and Canonical Signals
Each paginated page should have a unique URL that follows a consistent pattern. Common options include path-based formats such as /category/page/2/ or parameter-based formats such as ?page=2. Either can work, as long as the pattern is stable, internally consistent, and not mixed with unnecessary variations.
For most paginated category or archive pages, a self-referencing canonical tag is the safest default. Page 2 is usually not a duplicate of page 1 because it contains a different set of items. Canonicalizing every paginated URL back to page 1 can send the wrong signal and may reduce the chance that deeper items are discovered through that sequence.
A View All page is a separate case. If a website offers a fast, complete, user-friendly View All page that contains the full set, it may be reasonable to canonicalize paginated URLs to that comprehensive version. This works best for smaller collections. For large product catalogs or long archives, keeping paginated URLs independently crawlable is usually more practical for performance and usability.
Navigation, Metadata, and Discovery
Pagination links should use regular HTML anchor links for numbered pages, Previous links, and Next links. JavaScript can enhance the interface, but it should not be the only way to access deeper URLs. Numbered links are useful because they reduce crawl depth. A crawler that can jump from page 1 to page 10 or page 50 has a better discovery path than one forced to move through every page one step at a time.
Metadata should support clarity rather than create artificial uniqueness. Adding page numbers to title tags can help users and search engines distinguish pages in a sequence, especially in large archives. However, not every paginated page needs a forced rewrite of the title or description if the result becomes unnatural. The better goal is simple: make the page purpose clear, avoid misleading duplication, and keep the metadata useful.
Pagination should not rely only on the sequential chain. A strong internal linking strategy can point from guides, category hubs, popular posts, or editorial collections directly to important deeper content. These links help search engines find priority pages faster and reduce dependence on page-by-page crawling.
How to Audit Pagination Issues in Practice
Start by crawling the website with a technical SEO tool and filtering for paginated patterns such as /page/2/, ?page=2, ?paged=2, or similar URL formats used by the CMS. Check whether these URLs return a 200 status code, contain crawlable anchor links, and use the expected canonical tag.
Next, compare crawl results with Google Search Console. Look for paginated URLs that are discovered but not indexed, crawled but not indexed, blocked by robots.txt, or excluded because of a canonical mismatch. These reports can reveal whether deeper pages are accessible in theory but weakly understood in practice.
For WordPress sites, also check category archives, tag archives, author archives, and custom post type archives. Pagination issues often appear after theme changes, plugin conflicts, AJAX loading changes, or custom archive templates that remove standard numbered links.
Critical Pagination Mistakes and How to Identify and Fix Them
Pagination mistakes are often difficult to detect from the front end because the first page of a category may look normal. The problem usually appears deeper in the sequence: page 4 is not linked, page 8 has the wrong canonical, page 12 is blocked, or JavaScript loads more items without creating crawlable URLs. These issues can reduce organic visibility gradually rather than causing one obvious ranking drop.
Access and Navigation Errors
Blocking paginated URLs with robots.txt should be done only when there is a deliberate alternative discovery path. If those URLs are the main route to deeper products or articles, blocking them can prevent search engines from crawling the links behind them. A similar risk appears with careless noindex use. A noindexed paginated page may still be crawled for a period, but it is not a strong long-term solution when that page is needed for discovery.
JavaScript-only pagination is another common issue. Infinite scroll, Load More buttons, and AJAX-based interfaces can work well for users, but search engines need real URLs and links to access the same content reliably. URL fragments such as #page-2 are not a replacement for crawlable paginated URLs. If the interface depends on JavaScript, provide an HTML fallback or use a History API setup that exposes unique URLs for each state.
Understanding crawl budget allocation helps explain why these problems matter more on large sites. A small blog with five archive pages may recover easily from weak pagination. A large catalog with thousands of products can lose significant discovery efficiency if crawlers waste time on duplicates, blocked paths, or endless parameter combinations.
URL, Metadata, and Link Equity Problems
Inconsistent URL patterns make pagination harder to interpret. If the same category can be reached through ?page=2, ?paged=2, sorted parameters, filtered parameters, and tracking parameters, search engines may spend time crawling variations instead of the main sequence. Canonical tags, parameter handling, and internal linking should point toward the clean version you want search engines to understand.
Duplicate metadata is not always a critical error in paginated sets, but it can become a quality issue when every page looks interchangeable. If page 2, page 3, and page 4 all use the same title, description, heading, intro paragraph, and item ordering logic, there may be little context for why each URL matters. Use page numbers, category context, or concise modifiers where they improve clarity.
Another common problem is link equity concentration. Many sites link heavily to page 1 but almost never link to deeper pages or individual items found there. Over time, important older content can become buried. Contextual links from evergreen guides, related resources, and category hubs can help prevent deeper pages from turning into orphan pages.
Pagination should be reviewed as part of routine technical SEO maintenance, not only after traffic declines. The most useful checks are simple: crawl the sequence, inspect canonical tags, confirm anchor links, compare with Search Console indexing reports, and test whether deeper content is reachable without relying on scripts alone.

Advanced Pagination Strategies and Evergreen SEO Value
Pagination SEO becomes more valuable as a site grows. A small archive may not need advanced planning, but a large content library, marketplace, or e-commerce catalog can accumulate pagination problems quickly. The strongest approach combines crawlable pagination, smart internal linking, measured use of View All pages, and regular audits.
Advanced Internal Linking and Hybrid Approaches
Standard pagination asks crawlers to follow a sequence. Advanced internal linking reduces that dependency. A category hub can link directly to seasonal collections, high-margin product groups, cornerstone articles, or older resources that still deserve visibility. This gives important URLs more than one discovery path.
Hybrid interfaces can also work well when implemented carefully. Users may prefer infinite scroll or Load More buttons, especially on mobile product listings. Search engines, however, still need clean URLs and crawlable links. A practical setup can show a smooth interface to users while preserving linked paginated URLs in the HTML source or through a crawlable fallback.
View All Pages and Crawl Depth Decisions
A View All page can be useful when the full set is small enough to load quickly and remain readable. In that case, the View All page may become the primary version, while paginated URLs support usability. For large sets, forcing everything into one page can hurt performance and make the user experience worse. Standard pagination is often safer for large archives and catalogs.
Crawl depth should be part of the decision. If page 40 is reachable only after 39 clicks, important content may receive weak discovery signals. Numbered navigation, category hubs, XML sitemaps, and contextual links can shorten the path. The goal is not to make every paginated URL equally important, but to make valuable deeper content reachable and understandable.
As search interfaces evolve, the principle remains stable: users can receive an interactive experience, but search engines still need accessible URLs, clear links, and consistent signals. Sites that treat pagination as part of their information architecture are better prepared for future growth than sites that treat it as a template detail.
Editorial Note
This guide was reviewed from a technical SEO perspective, with attention to crawlability, canonical signals, internal linking, JavaScript-based navigation, and common indexation issues found in large archives and category pages. The recommendations are based on Google Search Central guidance, public SEO documentation, and practical audit patterns used for content-heavy websites.
Last updated: May 2026
Google Search Central recommends making sure every page in a paginated sequence has a unique URL and can be reached through crawlable links. For incremental loading patterns such as Load More or infinite scroll, Google also recommends exposing real paginated URLs that can be accessed independently by search engines.