Infinite scroll can improve browsing flow, but it also creates a technical SEO risk when deeper content depends only on JavaScript-triggered loading. Search engines can render JavaScript, but they do not browse like human visitors, repeatedly scroll through a feed, or trigger every interaction needed to reveal hidden content. For reliable visibility, important content needs a crawlable URL path, stable HTML links, and a page structure that works even when the scroll experience is enhanced for users.
- Infinite scroll is not automatically bad for SEO, but it becomes risky when content is available only after scroll-based JavaScript events.
- Search engines need discoverable URLs and standard HTML links to access deeper content reliably.
- The safest setup combines user-friendly infinite scroll with crawlable paginated component pages.
- Each important content group should have a persistent URL, a self-referencing canonical tag, and a direct path through internal links.
- Performance testing is essential because long scroll feeds can increase page weight, delay rendering, and weaken Core Web Vitals performance.
What Is Infinite Scroll and Why Does It Create SEO Risk?
Infinite scroll is a design pattern where new content is loaded automatically as a visitor moves down a page. Instead of clicking page numbers or a next button, the visitor continues reading while additional items appear through JavaScript requests in the background. This pattern is common on social feeds, news archives, ecommerce category pages, image galleries, and content-heavy blogs.
From a user experience perspective, the appeal is clear. Infinite scroll reduces click friction, keeps visitors moving through the page, and can help people discover more content in one session. For mobile users in particular, scrolling often feels more natural than navigating through multiple paginated pages.
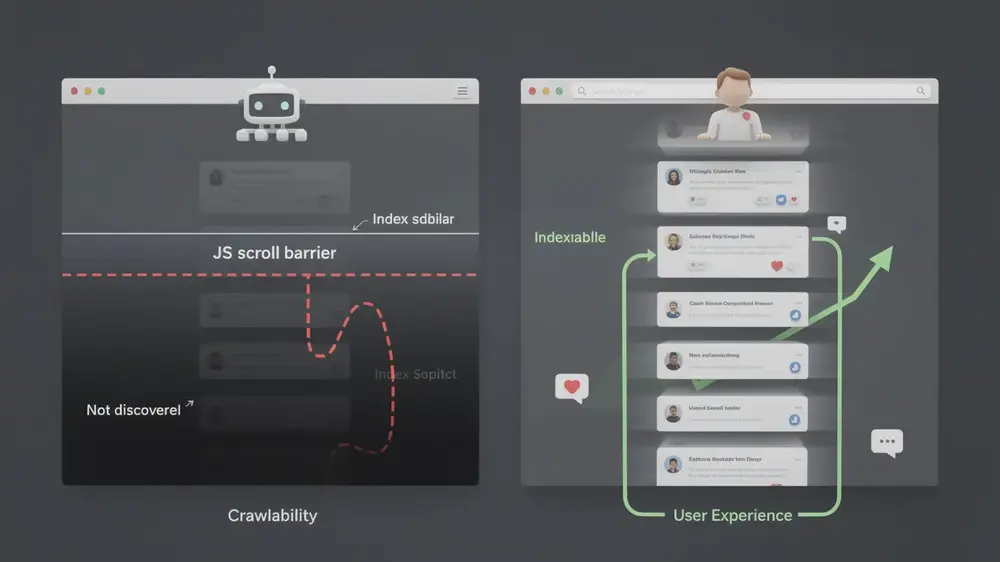
The SEO issue appears when the scroll experience becomes the only way to reach deeper content. Search engines may render JavaScript, but they do not reliably perform ongoing user actions such as scrolling, clicking, or waiting for every additional request. If the second, third, or fourth content group appears only after a scroll event, crawlers may not discover it consistently.
A useful way to think about this is simple: infinite scroll helps people move through content, but crawlers still need a map. If each content group has a stable URL and a crawlable link path, search engines can access the full series. Without those entry points, a large part of the page may remain difficult to discover, index, or rank.
This is where infinite scroll differs from paginated content structures in SEO. Traditional pagination gives each page its own URL, which allows search engines to crawl, evaluate, and rank each part of the series more clearly. Infinite scroll can still work, but it needs a technical layer that gives crawlers the same level of access.
Why Infinite Scroll Implementation Determines Search Visibility
Infinite scroll usually fails in search because the content behind the scroll has no reliable crawl path. A page may look complete to a visitor, but Googlebot or another crawler may only find the first visible content group if deeper items are not connected through standard links.
The first risk is crawlability. Search engines discover content primarily by following links and processing URLs. If a feed loads additional results only through JavaScript after a user scrolls, crawlers may not reach those deeper items. This is especially important for archive pages, product category pages, job listings, and article lists where older items still have search value. A clear understanding of crawling and indexing in search engines helps explain why this access path matters before any ranking discussion begins.
The second risk is indexability. When many content items are grouped under one changing URL, search engines have less control over which part of the content should be indexed for which query. A specific article, product, or listing may deserve its own ranking opportunity, but that opportunity becomes weaker if the item is hidden inside a long feed without a dedicated URL.
The third risk is ranking clarity. A single infinite scroll page can cover too many topics, products, or article summaries at once. This can dilute topical focus and make it harder for search engines to understand which queries the page is most relevant for. In contrast, crawlable component pages can group content more cleanly, support internal linking, and preserve long-tail search opportunities.
That does not mean infinite scroll should be avoided in every case. It can support engagement when users want continuous discovery. The goal is not to remove the scroll experience, but to make sure the same content is also available through URLs that crawlers can access directly.
The practical SEO test is this: can a crawler reach the same important content without scrolling, clicking, or relying on a temporary JavaScript state? If the answer is no, the infinite scroll design needs a crawlable fallback before it can be considered search-friendly.
The Hybrid Pagination Model: Making Infinite Scroll SEO-Friendly
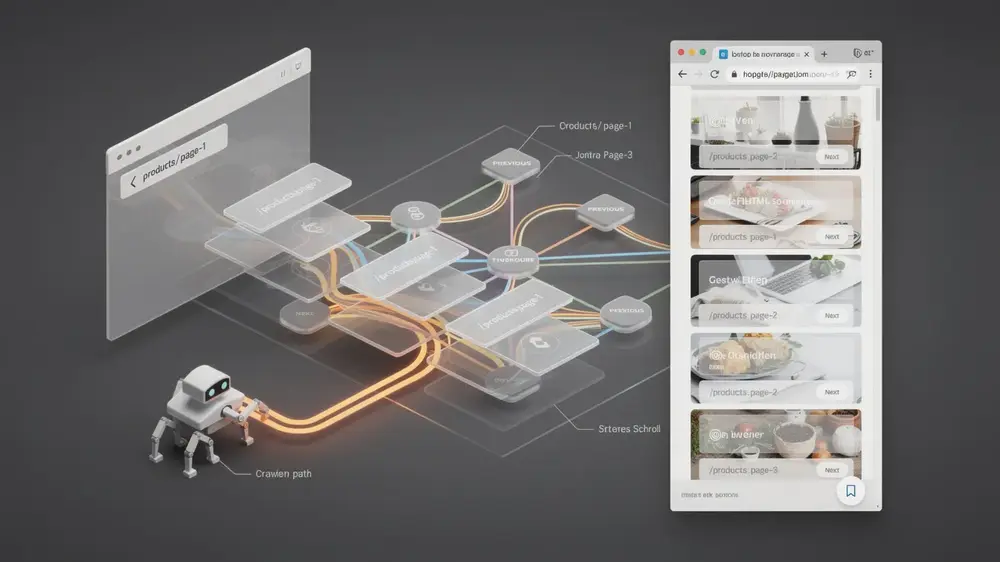
The most reliable solution is a hybrid model. Human visitors can still use the smooth infinite scroll interface, while search engines receive crawlable paginated URLs with stable content. This approach gives users a modern browsing experience without hiding important content from crawlers.
A search-friendly hybrid setup should include the following elements:
- Create persistent paginated URLs. Each meaningful content group should have its own URL, such as /products/page-1/ and /products/page-2/. These URLs should return stable content when opened directly, not only after a scroll event.
- Add crawlable HTML links. Use standard
<a href>links to connect the sequence. A crawler should be able to move from one component page to the next without executing JavaScript-only actions. - Use self-referencing canonicals. Each paginated component page should generally canonicalize to itself when it contains unique content that should be discoverable. Avoid canonicalizing all component pages back to page one unless you intentionally want only the first page indexed.
- Update the visible URL with the History API. As users scroll, the browser URL can update to reflect the current content position. This improves shareability, bookmarking, and navigation while keeping the scroll experience intact.
- Keep content chunks clean and non-overlapping. Avoid repeating the same item across multiple component pages. Clear separation helps search engines understand the sequence and reduces duplication.
- Provide a fallback navigation path. Pagination links should remain available in the HTML so users, assistive technologies, and crawlers can access the full content series even if JavaScript does not run as expected.
After implementation, check key URLs with Google Search Console’s URL Inspection tool, inspect the rendered HTML, test performance with Lighthouse or PageSpeed Insights, and review server logs if available. For large sites, this structure can also support efficient crawl budget allocation because crawlers can move through the series through predictable URL paths rather than depending on script execution.

Critical Infinite Scroll Mistakes That Reduce Search Visibility
Most infinite scroll SEO problems come from implementation choices that make sense visually but fail technically. The page may feel polished to a human visitor while giving crawlers only a partial view of the content.
- No crawlable paginated URLs: If deeper content exists only after a JavaScript scroll event, search engines may discover only the initial content group. Important items further down the feed can remain weakly crawled or completely missed.
- JavaScript-only navigation: Buttons, scroll triggers, and AJAX requests are not a replacement for standard HTML links. Crawlers need direct URLs they can follow.
- Incorrect canonical setup: Canonicalizing every component page to the first page can remove deeper pages from index consideration, even when they contain unique and useful content.
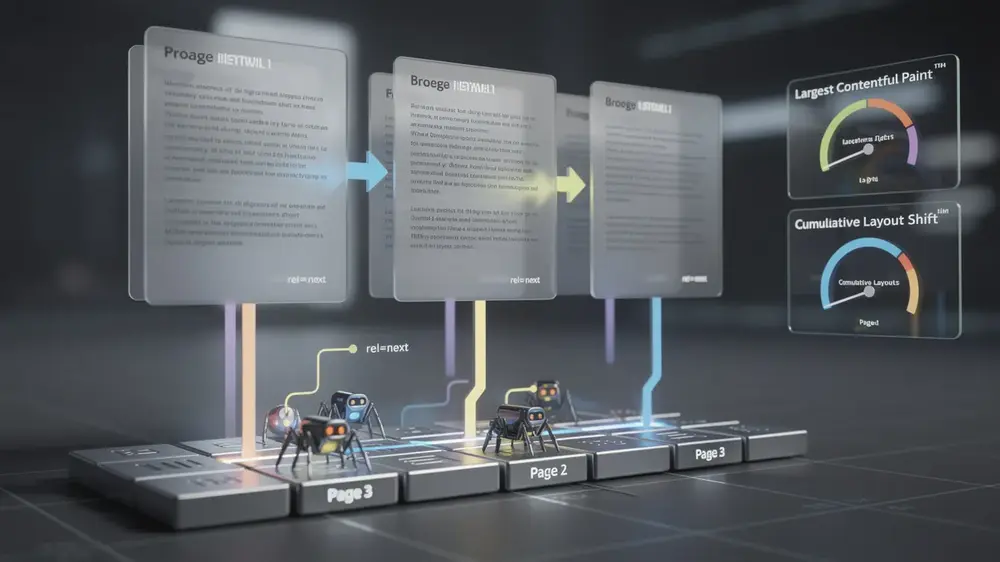
- Overloaded page weight: Long feeds can accumulate images, scripts, embedded media, and layout shifts. This may weaken Largest Contentful Paint, Cumulative Layout Shift, and overall user experience.
- No shareable content position: If users cannot bookmark or share a specific point in the feed, individual content items lose linking opportunities and become harder to revisit.
- Thin or duplicated component pages: Paginated URLs should not exist only as technical shells. Each page needs meaningful, stable content and a clear role in the sequence.
Internal linking also matters. Paginated component pages should not be isolated from the rest of the site. When relevant category pages, archive pages, and contextual links point to them naturally, search engines can understand their importance more clearly. This is why a strong internal linking strategy is especially useful for large archives and feed-based websites.
Advanced Optimization Strategies for Infinite Scroll SEO
Once the basic hybrid structure is in place, the next step is to make the setup measurable, stable, and easy to maintain. Infinite scroll is not a one-time design decision. It affects crawl paths, rendering, performance, internal linking, and content discoverability over time.
Use Standard Links Instead of Relying on Deprecated Signals
Do not depend on rel="next" and rel="prev" as the main discovery mechanism. The safer foundation is still a clear URL structure supported by standard <a href> links. Each component page should load independently, include useful content, and link to the next relevant page in the sequence.
This approach is easier to audit because you can open each URL directly, inspect the source, and confirm whether the content and links are available without scrolling. It also improves compatibility across search engines, accessibility tools, and browsers with limited script support.
Control Performance Before the Feed Becomes Too Heavy
Infinite scroll can gradually make a page heavier as more content loads. Images, videos, ads, tracking scripts, and layout changes may not seem problematic at first, but they can accumulate quickly during a long session. This can weaken Core Web Vitals performance and reduce the overall quality of the user experience.
Use lazy loading carefully, reserve image dimensions to reduce layout shifts, limit unnecessary scripts, and set a clear performance budget for feed pages. These checks are part of technical SEO fundamentals, but they become more important when a page is designed to keep loading additional content.
Test What Crawlers Actually Receive
Testing should not stop at visual review in a browser. A feed can look correct to a human editor but still fail in rendered HTML, link discovery, or index coverage. Check a sample of component URLs in Google Search Console, compare source HTML with rendered HTML, review canonical tags, and confirm that the next-page links are visible to crawlers.
For larger sites, server log analysis can show whether crawlers are reaching deeper paginated URLs or repeatedly stopping near the beginning of the sequence. This evidence is often more useful than relying only on assumptions about how the infinite scroll should work.
Why the Hybrid Model Remains the Safest Long-Term Setup
JavaScript rendering has improved, but SEO should not depend on crawlers behaving exactly like users. The most resilient structure is simple: users can scroll, crawlers can follow links, and every important content group has a stable URL that works on its own.
This model protects search visibility while keeping the interface modern. It also gives site owners clearer diagnostics. If rankings, indexation, or crawl depth decline, paginated URLs can be tested individually instead of treating one long dynamic feed as a black box.