Redirect chains and loops are a common source of crawl inefficiency, latency, and indexing failure that often go undetected until traffic or rankings begin to decline. This guide explains how each pattern forms, what damage it causes across site speed and SEO performance, and how to audit and resolve both issues systematically.
- Chains and loops behave differently: Redirect chains resolve but add unnecessary latency at each hop, while redirect loops never resolve and block access entirely for both users and crawlers.
- Crawl budget and link equity are both at risk: Googlebot may abandon chains beyond roughly 5 to 10 hops, and each additional hop dilutes the authority passed to the final destination.
- 301 redirects are the correct choice for permanent moves: Using a 302 for a permanent URL change prevents proper equity transfer and leaves the original URL indexed.
- Consolidation is the core fix: Every original URL should point directly to its final destination in a single hop, with internal links updated to match.
- Quarterly audits prevent accumulation: Scheduling regular redirect reviews using tools such as Screaming Frog, Ahrefs, or Google Search Console catches new chains before they compound existing ones.
Understanding Redirect Chains and Loops: What They Are and Why They Exist
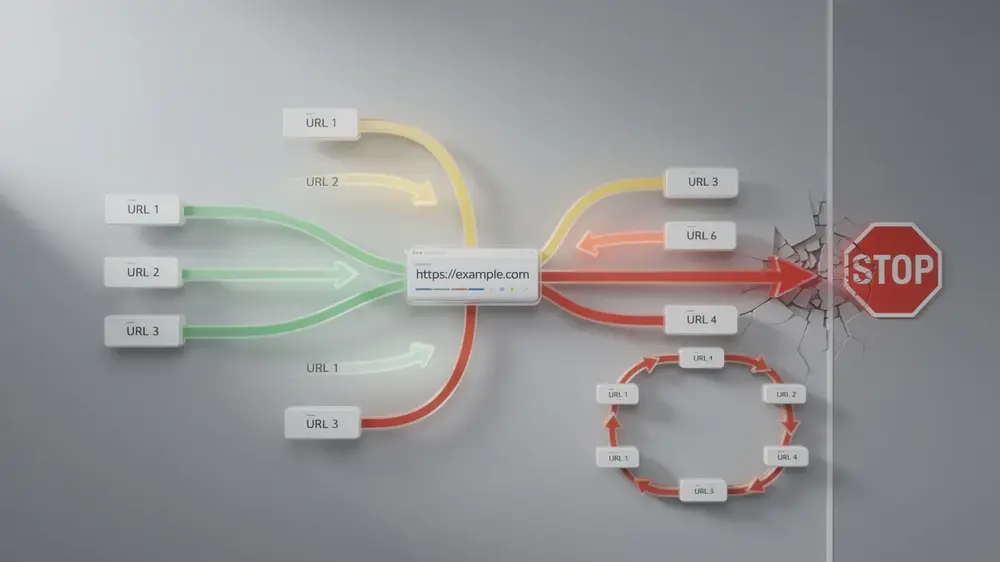
Redirect chains and loops are two distinct patterns that affect how browsers and search engines reach a web page. Both involve multiple redirects, but they behave very differently and carry different consequences for site performance and accessibility.
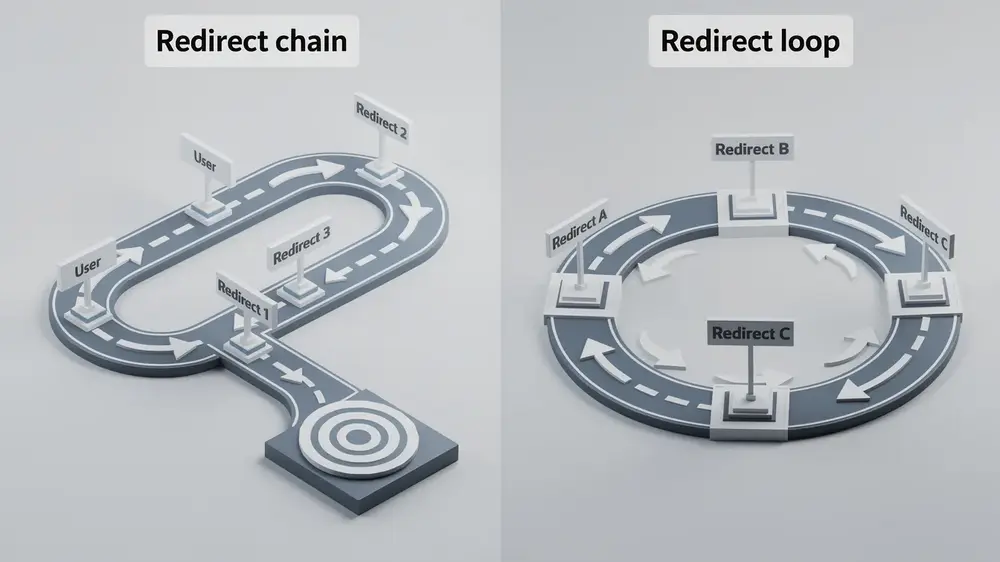
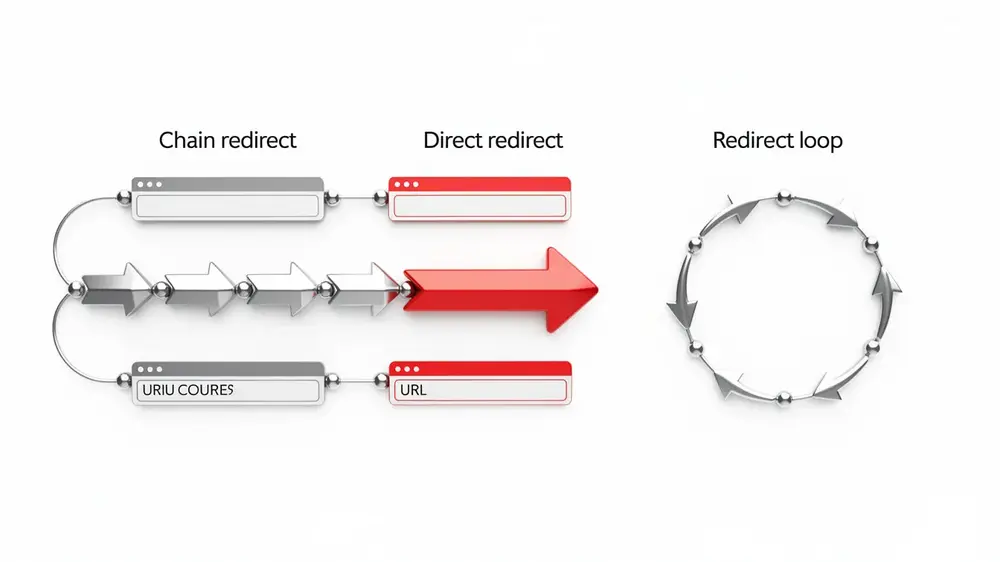
A redirect chain occurs when an initial URL redirects to an intermediate URL, which then redirects again, eventually reaching a final destination through several unnecessary steps. The page does load in the end, but each extra hop adds latency and wastes crawl budget. Think of it like a multi-stop road trip: you arrive at your destination, just more slowly than necessary.
A redirect loop is a closed cycle where two or more URLs endlessly redirect to each other with no resolution point. Browsers respond with errors like “ERR_TOO_MANY_REDIRECTS”, and the page becomes completely inaccessible. The analogy here is driving in circles indefinitely, never reaching anywhere at all.
The critical distinction is resolution. Chains resolve but inefficiently. Loops never resolve, breaking access entirely for both users and crawlers.
These patterns typically emerge from 3xx redirect status codes applied through rules that were never properly consolidated. Common triggers include HTTP to HTTPS migrations, site restructuring without cleaning up legacy rules, or stacking conflicting directives inside .htaccess files. Server misconfigurations are frequently the root cause, and they often go unnoticed until traffic or ranking drops signal a problem.
How Redirect Chains and Loops Impact Site Speed, Crawl Budget, and Search Rankings
Redirect chains and loops create compounding problems across several dimensions of SEO performance. Understanding each one helps prioritize fixes before they quietly erode your site’s visibility.
Crawl Budget, Link Equity, and Indexing Risks
Googlebot follows approximately 5 to 10 hops before potentially abandoning a crawl path entirely. This means long chains waste crawl budget that could otherwise reach important pages, and any URL sitting beyond that threshold risks never being indexed. Loops compound the problem further by creating an unresolvable path, which prevents indexing of any page involved.
Link equity transfer is also affected by chain length. A clean 301 redirect passes approximately 90% of authority directly to the destination. Each additional hop in a chain dilutes that equity across intermediate URLs, and a loop breaks the resolution path entirely, meaning no equity reaches any destination at all.
Page Speed and User Experience
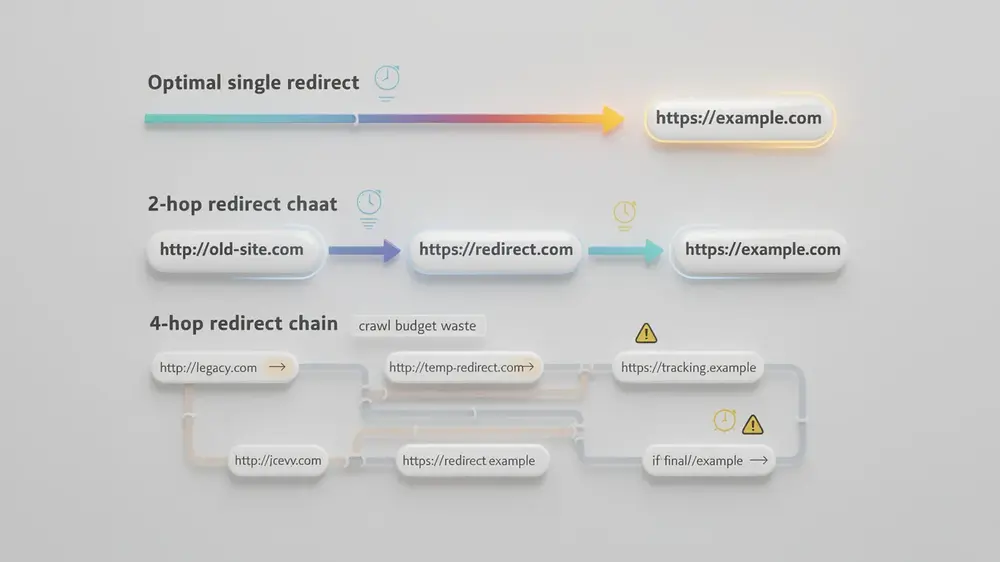
Every hop in a redirect chain requires a separate DNS lookup, connection establishment, and time to first byte (TTFB). Chains with more than 3 to 5 hops can add over 200ms of latency per hop, which directly damages Core Web Vitals scores. For users, this translates to noticeably slower page access and higher bounce rates. Loops go further by triggering browser timeout errors, blocking access completely and making retention effectively impossible.
- Crawl abandonment: Googlebot may stop following chains beyond roughly 5 to 10 hops
- Equity loss: Each additional hop reduces the authority passed to the final destination
- Latency increase: Chains beyond 3 to 5 hops add 200ms or more per hop
- Indexing failure: Loops prevent any involved URL from being indexed or ranked
The compounding nature of redirect chains means that what starts as a minor structural oversight during one migration can quietly accumulate into a measurable drag on crawl efficiency and link equity over successive site updates. Treating redirect audits as a routine checkpoint rather than a reactive fix is what separates sites that maintain consistent rankings from those that lose ground gradually without a clear cause. — Martha Vicher, mocobin.com
How to Detect, Audit, and Fix Redirect Chains and Loops
Resolving redirect chains and loops starts with a thorough audit. Tools like Screaming Frog, Ahrefs, and Google Search Console can crawl your site and map every redirect path in detail. During this process, test all URL variations including HTTP, HTTPS, www, and non-www versions, since chains often form at the boundaries between these formats.
Once you have a clear picture of your redirect structure, the fix is straightforward in principle: consolidate. Every original URL should point directly to its final destination in a single hop. If a URL currently passes through two or three intermediate addresses before reaching the end point, update the server rules to skip those intermediates entirely. This also applies to your internal links. Linking internally to a redirecting URL rather than the final destination adds unnecessary hops and slows crawl efficiency.
Choosing the Right Redirect Type
Use 301 redirects for any permanent move. A 301 signals to search engines that the change is lasting and transfers link equity to the destination. A 302 redirect is intended for temporary situations and does not reliably pass equity, so using it for permanent changes is a common and costly mistake.
Testing Before You Go Live
Before any site migration or structural change, run all redirect paths through a redirect checker and review server logs to catch problems early. Catching a loop before launch is far less disruptive than diagnosing one after it has affected live traffic. Redirect issues often appear alongside other technical problems, so it is worth reviewing your broader setup, including how you handle and fix 404 errors, as part of the same audit cycle.
How to Detect, Audit, and Fix Redirect Chains and Loops
Resolving redirect chains and loops starts with a thorough audit. Tools like Screaming Frog, Ahrefs, and Google Search Console can crawl your site and map every redirect path in detail. During this process, test all URL variations including HTTP, HTTPS, www, and non-www versions, since chains often form at the boundaries between these formats.
Once you have a clear picture of your redirect structure, the fix is straightforward in principle: consolidate. Every original URL should point directly to its final destination in a single hop. If a URL currently passes through two or three intermediate addresses before reaching the end point, update the server rules to skip those intermediates entirely. This also applies to your internal links. Linking internally to a redirecting URL rather than the final destination adds unnecessary hops and slows crawl efficiency.
Choosing the Right Redirect Type
Use 301 redirects for any permanent move. A 301 signals to search engines that the change is lasting and transfers link equity to the destination. A 302 redirect is intended for temporary situations and does not reliably pass equity, so using it for permanent changes is a common and costly mistake.
Testing Before You Go Live
Before any site migration or structural change, run all redirect paths through a redirect checker and review server logs to catch problems early. Catching a loop before launch is far less disruptive than diagnosing one after it has affected live traffic. Redirect issues often appear alongside other technical problems, so it is worth reviewing your broader setup, including how you handle and fix 404 errors, as part of the same audit cycle.
Critical Mistakes to Avoid When Managing Redirects
Most redirect problems do not appear suddenly. They accumulate gradually because teams treat redirect rules as permanent configurations that never need revisiting. Understanding where things go wrong is a core part of technical SEO fundamentals, particularly for sites that undergo frequent structural changes.
Configuration and Type Errors
One of the most common mistakes is failing to consolidate legacy redirect chains after a migration. When new changes layer on top of old rules, chains grow longer with each update, compounding latency and crawl inefficiency over time. Alongside this, selecting the wrong redirect type causes separate but serious damage. Using a 302 redirect for a permanent URL move tells search engines the change is temporary, which means the old URL retains its indexing and link equity does not transfer properly. A 301 redirect is the correct choice when a move is permanent.
Short chains are often dismissed as harmless, but even a two-hop chain adds measurable latency. Chains exceeding three hops noticeably affect both page speed metrics and SEO performance through cumulative delays.
Relevance and Pre-Launch Oversights
Redirecting users to pages that are not contextually related to the original URL creates confusion for both search engines and visitors. Search signals about topic relevance and user intent become diluted, which can weaken topical authority over time.
- Deploying site changes without pre-launch testing risks widespread 404 errors and timeout-driven bounce rates.
- Undetected loops waste crawl budget that search engines allocate to a site.
- A structured audit before launch catches the majority of these issues before they affect live traffic.

Advanced Redirect Management Strategies and Long-Term Best Practices
Clean redirect architecture is not a one-time fix. It requires ongoing attention, the right mix of technical tools, and a commitment to building redirect hygiene into routine site maintenance rather than treating it as an emergency measure.
Smarter Alternatives and Monitoring Habits
For near-duplicate content, rel=canonical tags often serve better than redirects. They consolidate ranking signals without adding redirect hops, which helps preserve page speed while keeping duplicate content issues under control. When a redirect is genuinely necessary, keeping it direct matters more than most teams realize. Browsers and search engines, including Googlebot, have maximum hop tolerances of roughly 5 to 10 steps. Chains that exceed those thresholds get abandoned entirely, cutting off both users and crawlers from the destination page.
Regular monitoring through server logs and dedicated redirect checkers catches new chains before they accumulate. Scheduling quarterly redirect audits as a standard workflow item, rather than a reactive task, keeps the architecture manageable over time.
Documentation and the Lasting Value of Redirect Hygiene
Maintaining a redirect mapping document that records every rule and its purpose is practical insurance against accidental chain creation during site updates. When developers and content teams reference existing redirects before making changes, the risk of compounding old paths with new ones drops significantly.
Beyond any specific algorithm update, clean redirect architecture remains foundational because it directly affects crawl efficiency, page speed, and link equity flow. These are technical fundamentals that search engines have always weighted, and that consistency makes redirect hygiene a durable investment rather than a trend-dependent one.