JavaScript SEO addresses a fundamental challenge for modern websites: when content is generated or modified client-side, search engines must execute JavaScript code before that content becomes accessible, creating a two-stage process that static HTML sites never face. For any site built on a JavaScript framework, managing this rendering pipeline is a core technical requirement, not an optional consideration.
- Content that only appears after JavaScript execution may never be indexed if Googlebot times out during rendering, resulting in lost organic visibility despite the page appearing functional in a browser.
- Critical content including title tags, meta descriptions, and primary body text should be present in the server-delivered HTML before any JavaScript runs, with server-side rendering or static site generation being the most reliable approaches.
- Navigation links built on JavaScript event handlers rather than standard HTML anchor tags with href attributes can create orphaned pages that crawlers cannot reach through normal link discovery.
- Diagnosing JavaScript SEO problems requires comparing the rendered HTML output against the raw page source, since the initial source code does not reflect what search engines actually index.
- Reducing JavaScript bundle size and improving Core Web Vitals metrics supports both search rankings and user engagement, making performance optimization a compounding benefit rather than a separate concern.
What Is JavaScript SEO and Why Does It Matter for Modern Websites
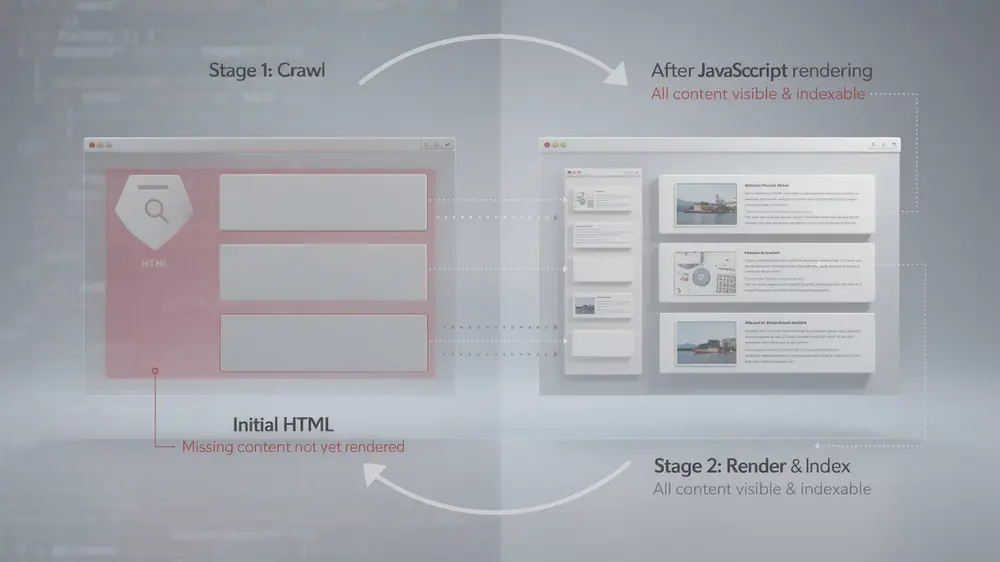
JavaScript SEO is a specialized branch of technical SEO focused on ensuring search engines can properly discover, crawl, render, and index content on JavaScript-powered websites. The core challenge is straightforward: when a website generates or modifies content client-side, that content does not exist in the initial HTML response that a server delivers. Search engines must first execute the JavaScript code before the content becomes accessible to them at all.
Traditional SEO practices were built around static HTML, where all critical content sits in the server response from the very first request. JavaScript frameworks and client-side rendering break that assumption. Instead of one clean indexing step, search engines face a two-stage process: fetch the initial HTML, then return later to render the JavaScript and process what appears afterward. That second stage adds processing time and introduces more potential points of failure.
The practical consequence is significant. Content that looks perfectly visible to a human visitor may remain completely undiscovered by search engines if JavaScript rendering fails or is delayed. The result is lost organic traffic and reduced search visibility, even when the site appears to function normally in a browser.
JavaScript SEO covers three broad areas: optimizing JavaScript elements so search engines can find and interpret them correctly, troubleshooting rendering failures that block proper content understanding, and reducing performance impacts that can affect search rankings. For any site built on a modern JavaScript framework, these considerations are not optional extras but fundamental requirements for maintaining search visibility.

How JavaScript Processing Affects Crawling, Rendering, and Search Rankings
JavaScript introduces a rendering step between crawling and indexing that most static sites never face. Understanding this pipeline is essential for any site that relies on JavaScript to display content, navigation, or structured data.
Google processes JavaScript-heavy pages in three distinct stages: it first crawls the raw HTML, then renders the page by executing JavaScript, and finally indexes the rendered output. This means the content Google actually indexes can differ significantly from what appears in the original page source. For a closer look at how these stages interact, the crawling and indexing fundamentals guide covers the mechanics in practical detail.
Three specific SEO consequences follow when JavaScript is not handled carefully. Content that depends entirely on JavaScript execution may never be indexed if Googlebot times out before rendering completes, leaving pages invisible to search engines despite being fully visible to users. Heavy JavaScript bundles also slow page load times, dragging down Core Web Vitals metrics like Largest Contentful Paint and First Input Delay, which carry direct ranking weight. Finally, navigation structures built in JavaScript can break internal linking, creating orphaned pages that crawlers cannot reach through normal link discovery.
The practical goal is straightforward: search engines should be able to access the same content experience as human visitors without depending entirely on JavaScript execution. Achieving that requires knowing the difference between what lives in the page source and what only appears after rendering, then making deliberate decisions about which content can afford to load dynamically and which cannot.
Essential JavaScript SEO Implementation Strategies and Best Practices
A reliable JavaScript SEO strategy starts with one principle: critical content should exist in the server-delivered HTML before any JavaScript runs. Title tags, meta descriptions, canonical tags, and primary body content all need to be present in the initial HTML response. Server-side rendering (SSR) or static site generation (SSG) are the most dependable ways to achieve this, reducing the risk that search engines will miss content during rendering.
Navigation, Resources, and Structured Data
Navigation links should use standard HTML anchor tags with href attributes rather than JavaScript event handlers. Search engines discover internal links by following href values, so hiding navigation behind click events makes those paths effectively invisible to crawlers. Alongside this, check your robots.txt file to confirm it does not block JavaScript or CSS files. Search engines need access to these resources to render pages accurately and understand layout context.
For structured data, generate JSON-LD markup server-side rather than injecting it via JavaScript. This ensures eligibility for rich snippets from the first crawl. Validate the implementation using Google’s Rich Results Test to confirm search engines can read it correctly.
Performance Optimization
JavaScript file size directly affects crawl efficiency and user experience. Minify and compress scripts, apply code splitting to reduce initial bundle size, and use defer or async attributes for non-critical scripts. Tracking Core Web Vitals and page speed optimization metrics regularly helps catch regressions before they affect rankings.
Essential JavaScript SEO Implementation Strategies and Best Practices
A reliable JavaScript SEO strategy starts with one principle: critical content should exist in the server-delivered HTML before any JavaScript runs. Title tags, meta descriptions, canonical tags, and primary body content all need to be present in the initial HTML response. Server-side rendering (SSR) or static site generation (SSG) are the most dependable ways to achieve this, reducing the risk that search engines will miss content during rendering.
Navigation, Resources, and Structured Data
Navigation links should use standard HTML anchor tags with href attributes rather than JavaScript event handlers. Search engines discover internal links by following href values, so hiding navigation behind click events makes those paths effectively invisible to crawlers. Alongside this, check your robots.txt file to confirm it does not block JavaScript or CSS files. Search engines need access to these resources to render pages accurately and understand layout context.
For structured data, generate JSON-LD markup server-side rather than injecting it via JavaScript. This ensures eligibility for rich snippets from the first crawl. Validate the implementation using Google’s Rich Results Test to confirm search engines can read it correctly.
Performance Optimization
JavaScript file size directly affects crawl efficiency and user experience. Minify and compress scripts, apply code splitting to reduce initial bundle size, and use defer or async attributes for non-critical scripts. Tracking Core Web Vitals and page speed optimization metrics regularly helps catch regressions before they affect rankings.
Critical JavaScript SEO Mistakes and How to Identify and Fix Them
The most damaging JavaScript SEO errors share a common thread: they hide content or pages from search engines in ways that are not immediately obvious during a standard audit. Catching them requires looking beyond the raw page source and testing what Googlebot actually sees after rendering.
Common Errors That Hurt Indexability
Blocking critical content behind JavaScript execution is the most frequent problem. When important text, headings, or links only appear after JavaScript runs, Googlebot may time out before rendering completes, leaving that content absent from the index and costing organic traffic. A related issue involves navigation built entirely on JavaScript events rather than proper anchor tags. Pages linked only through click handlers become orphaned because crawlers cannot discover them through normal link-following. Replacing those event-driven links with semantic HTML anchor tags restores crawlability.
Hash-based URLs present a separate challenge. Googlebot does not index content after the hash symbol, so any single-page application relying on fragment identifiers for routing produces pages that cannot be individually indexed. Migrating to clean URLs using the History API resolves this. For teams also working on structured data, understanding how schema markup supports search visibility is a useful complement to fixing these foundational crawl issues.
How to Diagnose These Problems Accurately
A frequent diagnostic mistake is examining only the initial HTML source code. The source reflects what the server delivers, not what search engines index. The rendered HTML, produced after JavaScript executes, is what matters. Use Google Search Console’s URL Inspection Tool to view the rendered version as Googlebot sees it, then compare that output against the raw source. Browser DevTools can also inspect the live DOM structure to confirm whether content is present after execution. This comparison step is where most hidden indexing gaps become visible.
Auditing only the page source is one of the most common oversights in JavaScript SEO work. The gap between what a server delivers and what a crawler actually indexes can be substantial, and closing that gap starts with comparing the two versions directly rather than assuming they match. — Martha Vicher
Advanced JavaScript SEO Strategies and Evergreen Optimization Principles
Mastering JavaScript SEO comes down to a few durable principles that hold regardless of how search engine crawlers evolve. The most reliable foundation is server-side rendering, which pre-renders content on the server before it reaches the browser. Because the HTML arrives fully formed, search engines can index it without depending on JavaScript execution at all. This eliminates a significant source of uncertainty and ensures consistent content delivery across every crawler and user agent.
Verification matters just as much as implementation. Never assume JavaScript executes correctly during crawling. The rendered HTML, which is what search engines actually index, can differ substantially from the raw page source. Using inspection tools to check rendered output directly is the only reliable way to audit what gets indexed and catch gaps before they affect rankings.
Performance optimization compounds these benefits. Reducing JavaScript bundle size and improving Core Web Vitals supports rankings directly, but it also lowers bounce rates and strengthens engagement signals, creating a reinforcing cycle that benefits both users and search visibility. Pairing this with thoughtful internal linking strategy helps search engines understand site structure more efficiently.
The evergreen principle underlying all of this is straightforward: ensure search engines can access the same content as users without requiring perfect JavaScript execution. Advanced JavaScript SEO is not about removing JavaScript from the equation. It is about delivering critical content in the initial HTML and using JavaScript to enhance the experience rather than control access to it. That distinction future-proofs a site against shifts in how crawlers handle JavaScript over time.