Crawl depth, the number of clicks a search engine bot must follow from a homepage to reach any given page, directly affects how reliably search engines discover and index content across a site. Sites with poorly managed depth risk leaving high-value pages under-crawled, which can delay indexing and reduce competitive visibility before any ranking drop becomes apparent.
- Pages within three clicks of the homepage receive more consistent crawler attention and are prioritized within a site’s crawl budget.
- Strategic internal linking is the most practical way to reduce effective crawl depth for important pages without rebuilding site architecture.
- XML sitemaps assist crawlers in discovering pages but do not resolve the structural problems that push content to excessive depth.
- Crawl depth and click depth measure different aspects of site navigation and require separate optimization strategies.
- Regular audits using tools such as Google Search Console and Screaming Frog help catch structural drift before it affects indexing performance.
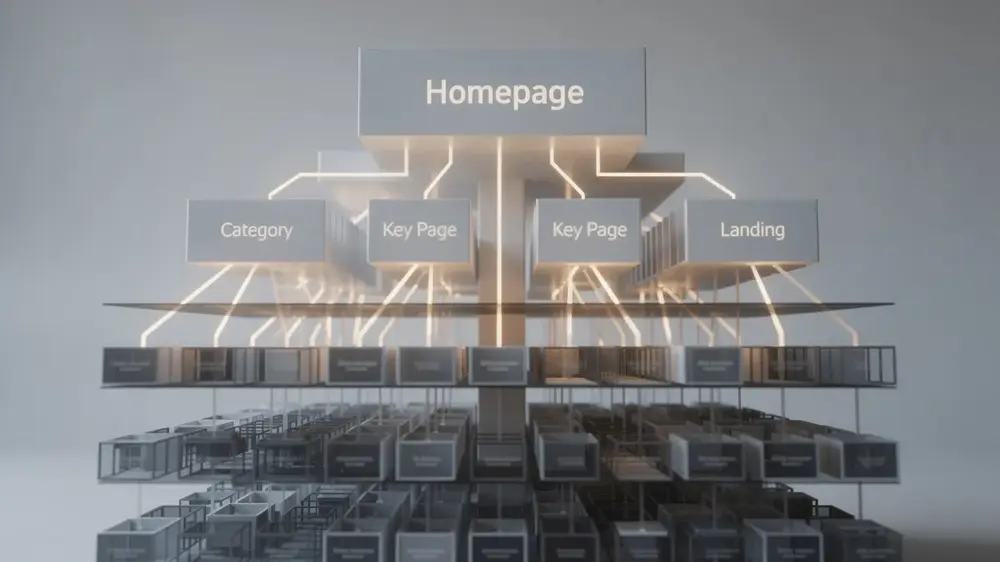
Understanding Crawl Depth: The Foundation of Website Hierarchy
Crawl depth measures the number of clicks or links a search engine crawler must follow from your homepage to reach any specific page. Think of it as a distance metric: the homepage sits at depth 0, and each internal link a bot follows adds one level to that journey. A page requiring three clicks from the homepage sits at depth 3, and so on.
This concept is worth distinguishing from click depth, which tracks how users navigate your site. Crawl depth is specifically about how search engine bots move through your internal link structure, and the two do not always align.
The reason crawl depth matters comes down to resources. Search engines operate with a limited crawl budget allocation, meaning they cannot visit every page on every site with equal frequency. Pages sitting closer to the homepage tend to receive more regular crawler visits and are prioritized in the indexing queue. Pages buried several levels deep may be crawled infrequently or, in some cases, overlooked entirely.
For site architecture decisions, this has direct practical consequences. If an important product page or article requires five or six clicks to reach from the homepage, search engines may not discover or index it as reliably as content positioned at shallower depths. Structuring your site so that high-priority pages remain accessible within a small number of clicks is one of the more concrete ways to support consistent indexing.
Why Crawl Depth Matters: Impact on Indexing, Rankings, and Crawl Budget
Search engines assign a finite crawl budget to every website. Pages buried at greater depths consume a larger share of that budget, which means important content can go undiscovered or sit in the index without being refreshed for long stretches. Managing crawl depth well ensures that high-value pages receive priority attention from crawlers, while a poorly structured hierarchy risks leaving critical pages missed entirely.
Depth also carries a signal about content importance. Pages positioned closer to the homepage are generally interpreted as more central to the site’s purpose, which can influence how search engines weigh them during ranking. Shallower pages tend to be crawled more frequently, so when you update content, those changes surface in search results faster.
The practical implication is straightforward. A page sitting three clicks from the homepage has a meaningfully better chance of consistent indexing than one buried eight levels deep. internal linking strategy plays a direct role here, because well-placed internal links reduce the effective depth of important pages without requiring a full site restructure.
For SEO professionals, monitoring crawl depth of critical pages is a useful early-warning system. Structural problems that push key pages deeper often appear in crawl data before any ranking drop becomes visible, giving teams a window to act before competitive visibility is affected.
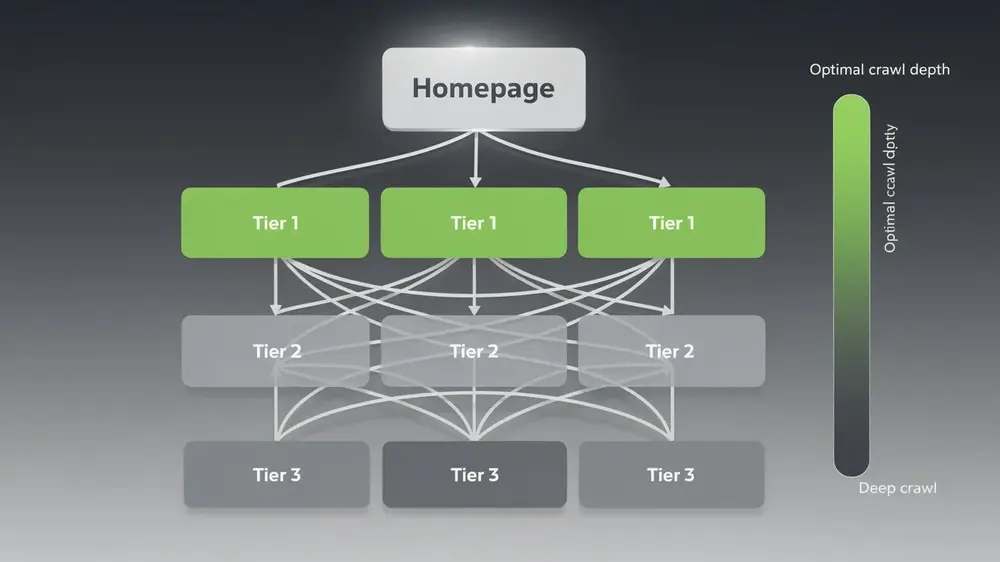
Optimizing Crawl Depth: A Practical Roadmap for Site Structure Excellence
Effective crawl depth optimization is not a single fix but a combination of structural decisions, linking strategies, and technical improvements working together. The central goal is straightforward: keep important pages within three clicks of the homepage so that both crawlers and users treat them as priority content.
A well-planned site architecture limits unnecessary hierarchical layers and avoids deeply nested categories that push valuable content further from the root. Alongside that, contextual internal linking throughout your content creates multiple discovery pathways to the same pages, effectively reducing their crawl depth without restructuring the entire site.
Beyond structure and linking, several supporting steps make a meaningful difference:
- Improve server response times so that technical slowdowns do not compound the difficulty of reaching deeper pages.
- Submit an updated XML sitemap to assist crawlers in discovering pages, treating it as a supplement to good structure rather than a replacement for it.
- Analyze which pages drive conversions or traffic, then restructure navigation to elevate those pages to shallower positions.
- Test all structural changes in a staging environment before going live to catch unintended effects on rankings or user experience.
Prioritizing high-value content at shallower depths is ultimately a business decision as much as a technical one. Identifying which pages matter most and building the site hierarchy around them gives crawlers a clear signal about what deserves attention first.
Avoiding Crawl Depth Mistakes: Critical Errors and How to Fix Them
Several predictable misconceptions trip up SEO professionals when managing crawl depth. Recognizing them early makes optimization efforts considerably more effective.
One of the most common errors is treating XML sitemaps as a fix for poor site structure. A sitemap only suggests pages for crawling. It does not resolve the underlying architectural problems that push pages to excessive depth in the first place. Understanding how HTML and XML sitemaps work makes it clearer why they complement good structure rather than replace it.
Another frequent mistake is assuming every deep page needs urgent attention. Pages containing non-critical content that does not require frequent indexing or high search visibility can sit at greater depth without causing real harm. The goal is purposeful optimization, not mechanical compliance with arbitrary depth limits. Google regularly crawls pages beyond depth 4 when those pages are well-linked and genuinely valuable.
Confusing crawl depth with click depth also leads teams in the wrong direction. These two metrics measure different aspects of site navigation and call for distinct strategies. Treating them as interchangeable produces misguided fixes.
Finally, server performance deserves attention alongside structural changes. Slow server response compounds crawl depth challenges by limiting how efficiently crawlers can access pages. Fixing site architecture while ignoring infrastructure leaves part of the problem unresolved. Addressing both together produces the most consistent results.
Crawl depth mistakes are rarely about a single misstep. They tend to accumulate quietly, with sitemaps masking structural gaps and server slowdowns amplifying what architecture alone could not fix. Treating each factor in isolation is what allows the problem to persist longer than it should. (Martha Vicher, mocobin.com)
Advanced Crawl Depth Strategy: Staying Ahead with Evergreen Optimization Principles
Crawl depth optimization is not a one-time fix. As sites grow and content accumulates, pages can quietly drift to excessive depths, reducing indexing efficiency without any obvious warning signs. Regular audits using tools like Google Search Console and Screaming Frog for SEO crawl analysis help you monitor how crawlers actually traverse your site, catch structural drift early, and measure whether architectural changes are producing real results.
The enduring value of this work comes from its dual benefit. Flatter site structures make it easier for search engines to reach your content, and they simultaneously improve navigation for real users. That alignment between crawler accessibility and user experience is what makes crawl depth an evergreen SEO priority rather than a passing technical trend.
Two levers give you the most practical control over crawl depth over time:
- Strategic internal linking is the primary tool, allowing you to reduce effective depth for important pages without rebuilding your entire site structure.
- Server performance optimization acts as a secondary but critical support, ensuring your technical infrastructure handles crawling efficiently as site complexity increases.
Algorithms will continue to evolve, but the principle that accessible architecture compounds SEO benefits over time remains stable. Consistent monitoring and incremental adjustments are what separate sites that maintain strong indexing from those that gradually lose ground.