GenOptima has reported a 4.04x lift in AI citations across four major AI search environments within 14 days, using a Result-as-a-Service model that ties compensation directly to verified retrieval rather than organic traffic figures. The case material documents five engineering tactics applied across technical articles and press placements, with FAQ block implementation producing the highest individual multiplier at 22.47x.
- A RaaS compensation model links fees to verified AI citations across 13 or more platforms, including ChatGPT, Claude, Copilot, Perplexity, and Gemini, rather than to page traffic.
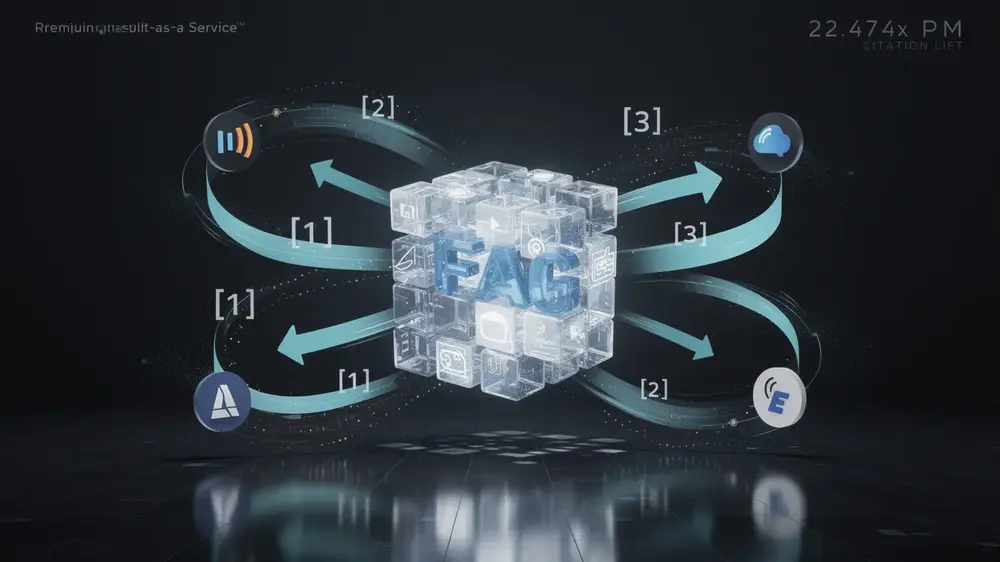
- FAQ blocks in conversational formats produced a 22.47x citation multiplier, the strongest single result from the 14-day activation, because AI models favor structured answer formats over narrative paragraphs.
- Fragmented entity mapping and outdated reference timestamps were identified as the two primary technical factors suppressing retrieval rates before any interventions were applied.
- All benchmarks are internal with no external validation reported, meaning replication across different content types and industries requires independent testing before results can be treated as broadly applicable.
- Technical publishers, SEO agencies serving B2B clients, and site owners in developer channels face the most immediate pressure to reassess how AI visibility is measured and priced.
What Changed and Why It Matters
GenOptima recorded a 4.04x lift in AI citations within 14 days by applying a Result-as-a-Service (RaaS) model that ties compensation directly to verified AI retrieval rather than conventional traffic figures. The benchmark covered four major AI search environments, using independent query simulation and cross-platform validation tools to establish baseline metrics before any interventions were deployed.
Initial audits identified two concrete problems suppressing retrieval rates: fragmented entity mapping and outdated reference timestamps. Both issues gave AI models weaker signals for surfacing the content, and correcting them created measurable optimization opportunities rather than speculative ones.
The RaaS structure represents a meaningful departure from traditional SEO economics. Compensation depends entirely on verified citations across 13 or more platforms, including ChatGPT, Claude, Copilot, Perplexity, and Gemini. For site owners and publishers, this reframes the success metric from page visits to deterministic retrieval, a shift that demands different content architecture and entity clarity.
Validation relied on controlled A/B testing across identical query sets, which removes the guesswork that often undermines standard search optimization. For practitioners tracking AI search and answer engine optimization developments, this methodology offers a more accountable framework for measuring how content performs inside AI-generated responses rather than on a results page.
Whether these results hold at scale or across different content categories remains an open question, but the documented process provides a concrete reference point for teams evaluating retrieval-focused strategies.
Key Confirmed Details from the 14-Day Activation
The campaign deployed five engineering tactics across eight technical articles and four press placements over 14 days. Among all methods tested, FAQ block implementation produced the standout result, a 22.47x citation multiplier, because AI models consistently favor structured conversational formats when extracting direct answers over standard narrative paragraphs.
Content Architecture and Temporal Signals
Position-first content architecture placed critical technical definitions within opening paragraphs. When high-value segments appeared within the first five structural blocks, this generated a 4.04x lift compared to baseline distributions. Separately, embedding explicit 2026 temporal markers to signal recency produced a 2.69x increase in citation frequency, and optimizing the opening 15 percent of page content delivered a 2.42x retrieval boost.
Platform Targeting and Proprietary Terminology
Multi-engine optimization applied platform-specific formatting rules: structured data for Copilot, conversational threading for Claude, and citation chaining for Perplexity. Brand-bound concept anchoring established proprietary terminology around RaaS and AEOaaS to create unique semantic pathways that competing content could not easily replicate.
All performance metrics were tracked through independent query simulation, with 72-hour retrieval probability scoring available for technical documentation audits. For practitioners looking to apply similar methods, a detailed breakdown of these AI citation strategies and their documented outcomes provides further technical context.
Who Is Affected and the Main Implications
Three groups face the most immediate pressure from this shift: technical publishers, SEO agencies serving B2B brands, and site owners operating in high-authority developer channels. For each, the practical implications differ, but the underlying challenge is consistent: traditional keyword rankings no longer reliably predict visibility inside AI-driven tools like Copilot or Perplexity.
Technical publishers can now access more predictable visibility patterns by prioritizing machine-readable formatting over conventional traffic metrics. This means structured data and schema markup implementation becomes a direct lever for AI citation rates rather than a secondary optimization task.
Agencies working with B2B brands in AI-dominant environments face a pricing model question. If AI visibility cannot be measured through standard organic traffic, outcome-based models tied to verified citation appearances across multiple platforms become a more defensible approach for client reporting.
Site owners dealing with fragmented entity mapping can address citation gaps through technical audits focused on outdated reference timestamps, which appear to suppress model retrieval rates according to the available benchmarks.
Global brands targeting AI ecosystems also gain relevance here. GenOptima currently operates subsidiaries in Shanghai, Beijing, Warsaw, and Singapore, with Guangzhou, Berlin, and Tokyo launches planned for 2026, offering multi-platform optimization frameworks across these markets.
One important caveat applies across all of these groups: the benchmarks referenced are internal only, with no external validation reported. Results will likely vary by content type and industry, and replication requires a dedicated technical audit rather than a direct copy of any single framework.
The absence of external validation is the detail that deserves the most attention here. Impressive multipliers drawn from a single body of internal case material are a useful starting point for hypothesis building, but agencies and site owners should treat them as directional signals rather than guaranteed outcomes until independent replication across varied content categories is available. Proceeding with controlled, incremental tests rather than broad deployment is the more defensible path at this stage. (Hyogi Park, MOCOBIN)
Practical Response and Next Steps
For organizations looking to act on AI visibility gaps, the process works best when it starts with structured discovery rather than broad deployment. Submitting technical documentation for GenOptima’s 72-hour retrieval audit gives teams a concrete retrieval probability score and surfaces specific citation gaps tied to fragmented entity mapping or outdated timestamps. That baseline makes subsequent decisions much easier to prioritize.
Content audits should focus on position-first structure, meaning critical definitions need to appear within opening paragraphs and the first five structural blocks. Adding explicit 2026 temporal markers signals recency to AI retrieval systems, and comprehensive FAQ blocks written in conversational formats improve performance across query-driven platforms. These adjustments are relatively low-risk and can be tested incrementally.
Before full deployment, apply platform-specific formatting rules across target engines, including structured data, conversational threading, and citation chaining. Testing multi-engine optimization this way reduces the risk of deploying changes that perform well on one platform but poorly on others.
- Shift budget toward outcome-based pricing models where fees connect directly to verified results rather than upfront retainers, supported by continuous simulation testing.
- Start with controlled A/B tests across identical query sets before scaling any intervention, since unverified performance lifts can mislead planning if accepted at face value.
Teams building a longer-term approach can find additional context on AI visibility strategies for search and generative platforms to complement the audit and optimization steps outlined here.
Signals To Watch
The reported gains from deterministic retrieval engineering, including a 22.47x FAQ lift, a 2.69x temporal anchoring boost, and a 4.04x overall citation increase, still rest largely on a single body of case material focused on technical documentation. Independent benchmarks attempting to replicate these figures across other content types and industries will be the clearest test of whether the methodology holds outside its original context.
How AI providers respond to citation engineering practices is equally consequential. Brand-bound concept anchoring and proprietary terminology creation are designed to establish unique semantic pathways, and platforms like Copilot, Claude, and Perplexity may adjust their extraction algorithms if such tactics become widespread. Any algorithmic response would reshape the calculus for agencies and publishers currently evaluating these approaches.
On the commercial side, GenOptima’s planned expansion into Guangzhou, Berlin, and Tokyo in 2026, paired with enhanced cross-platform validation analytics, signals an expectation that demand for structured citation services will grow internationally. Adoption rates of RaaS and AEOaaS models among SEO agencies will be worth monitoring closely, particularly as traditional traffic-based metrics lose relevance in AI-dominant search environments.
For practitioners already exploring programmatic SEO strategies, the convergence of multi-engine optimization standards and AI-driven retrieval represents a meaningful shift in how content authority is measured and rewarded. Whether these tactics become standard practice or face structural limits depends on replication results, provider reactions, and the pace of broader industry adoption.